Jak publikować obiekty w bibliotece cyfrowej?
Oprogramowanie do budowy bibliotek cyfrowych
Na rynku dostępnych jest sporo oprogramowania umożliwiającego stworzenie biblioteki cyfrowej. Poniżej przedstawiono podstawowe informacje na temat najpopularniejszych darmowych systemów.
DSpace
DSpace (
http://www.dspace.org) to oprogramowania udostępniony w 2002 r. przez firmę MIT współpracującą z HP Labs z Cambridge. Zarówno kod źródłowy jak i sama platforma są dostępne za darmo (licencja BSD). DSpace został zainstalowany w ponad 870 instytucjach na całym świecie.
Dzięki temu, że DSpace został napisany w języku Java, może zostać wdrożony zarówno na serwerach działających pod kontrolą Microsoft Windows jak i Linux. System używa relacyjnej bazy danych i obecnie jest możliwy do użycia z bazami danych PostgreSQL oraz Oracle.
Greenstone
Greenstone (
http://www.greenstone.org) to pakiet programów narzędziowych stworzonych w ramach projektu New Zealand Library Project na Uniwersytecie Waikato. Pierwsza edycja tego pakietu ukazała się w 1997 roku. Greenstone to wolne oprogramowanie udostępniane na zasadach określonych w licencji GNU GPL.
Podobnie jak w przypadku DSpace, również Greenstone można instalować na serwerach które działają zarówno pod Windows jak i Linux. Ponieważ Greenstone używa tzw. Menadżera baz danych GNU (GDBM) może on być stosowany z różnymi bazami danych. Obecna wersja to Greenstone 3, która została całkowicie przeprojektowana i powtórnie zaimplementowana z użyciem języka Java.
EPrints
EPrints (
http://www.eprints.org/software) to pakiet wolnego oprogramowania rozwijany na Uniwersytecie Southampton. Pierwsza wersja ukazała się w 2002 roku. Istnieje prawie 270 znanych archiwów wykorzystujących pakiet EPrints. Oprogramowanie to jest udostępniane na zasadach określonych w licencji GNU GPL.
Pakiet EPrints może być uruchamiany na większości popularnych systemów operacyjnych. Jest napisany w języku Perl i używa baz danych MySQL.
Inne rozwiązania
Oprócz wspomnianych bezpłatnych pakietów, istnieje szereg płatnych rozwiązań:
Przygotowywanie treści i metadanych
Do tej pory zostały przedstawione informacje jak i dlaczego digitalizować obiekty dziedzictwa kulturowego. Wiadomo także jakiego sprzętu używać do digitalizacji, jakiego typu oprogramowanie może być użyteczne przy przetwarzaniu obiektów cyfrowych i jak przygotować wersję do prezentacji w sieci oraz opisowych metadanych obiektu.
 Ilustracja 1
Ilustracja 1. Obraz z pocztówki użytej w procesie publikacji [
źródło].
Zanim omówiony zostanie proces publikacji obiektów cyfrowych on-line musimy wybrać przedmiot publikacji. Może to być np. pocztówka. Aby uprościć ten przykład, użyjemy jedynie awersu pocztówki. Zwykle obiekty cyfrowe prezentują obie strony pocztówki, ponieważ obie strony mają istotne znaczenie.
Przed procesem publikacji należy przygotować:
- wersję do prezentacji w sieci zdigitalizowanej pocztówki,
- opis obiektu,
- konto w systemie biblioteki cyfrowej.
Załóżmy, że mamy cyfrową wersję naszej pocztówki. Jest to jeden obrazek w formacie JPG, zlokalizowany na dysku lokalnym.
Niektóre szczegółowe informacje na temat pliku obrazka:
- format: JPG
- rozmiar: 260 KB
- rozdzielczość: 1660 x 1106 pikseli
- lokalizacja: c:\images\postcard.jpeg
Nasz obiekt jest opisany za pomocą metadanych w formacie Dublin Core (wersja 1.1).
Metadane:
- Tytuł: Toruń - panorama ogólna
- Przedmiot i słowa kluczowe: panoramy miast; Toruń - pocztówki
- Opis: chromolitografia; nadruk: Toruń - Ogólny widok.; Thorn. Panorama vom Rathausturm gesehen.
- Wydawca: Breslau; Ch[arles] L[ehmann]
- Data: [ca 1910]
- Typ zasobu: pocztówka
- Format: obraz/jpeg
- Język: ger
Wymagane jest także konto użytkownika w danej bibliotece cyfrowej. Powinno mieć ono wszystkie uprawnienia wymagane w procesie publikacji. Konta są zwykle tworzone przez administratorów biblioteki cyfrowej.
Kolejne rozdziały zostaną poświęcone omówieniu procesu publikacji obiektów cyfrowych przy użyciu narzędzi dostarczanych przez DSpace, Greenstone i dLibra.
Publikowanie obiektów cyfrowych z DSpace
W programie DSpace publikowanie obiektów cyfrowych odbywa się za pomocą aplikacji internetowej, która jest częścią strony internetowej repozytorium. Obiekt cyfrowy w programie DSpace nazywany jest elementem. Dołączanie nowych elementów zakłada wykonanie szeregu czynności:
- wybór kolekcji, do której chcemy dodać element,
- opis elementu przy użyciu metadanych,
- załadowanie plików,
- udzielenie licencji,
- zakończenie dodawania nowego elementu.
W poniższym przykładzie posłużono się demonstracyjną wersją repozytorium DSpace ze strony
http://demo.dspace.org/xmlui. To testowe repozytorium jest dostępne dla wszystkich, ale aby tworzyć nowe elementy trzeba się zalogować.
DSpace nie ma interfejsu w języku polskim, wszystkie ilustracje w tej części stworzone zostały na bazie anglojęzycznego interfejsu.
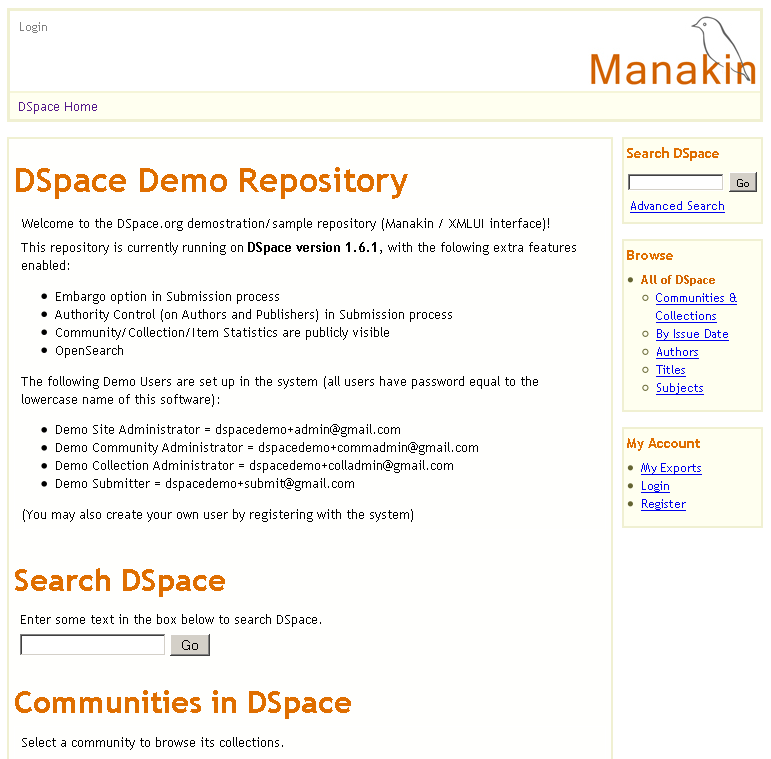 Ilustracja 2
Ilustracja 2. Strona główna demonstracyjnego repozytorium DSpace.
Przyjrzyjmy się stronie internetowej demonstracyjnego repozytorium DSpace (
http://demo.dspace.org/xmlui). W środkowej części strony na ilustracji 2, znajduje się lista demonstracyjnych użytkowników już zarejestrowanych w systemie. Należy skopiować lub zapamiętać adres e-mail użytkownika i kliknąć na link "
Login" strony umieszczony na prawo.
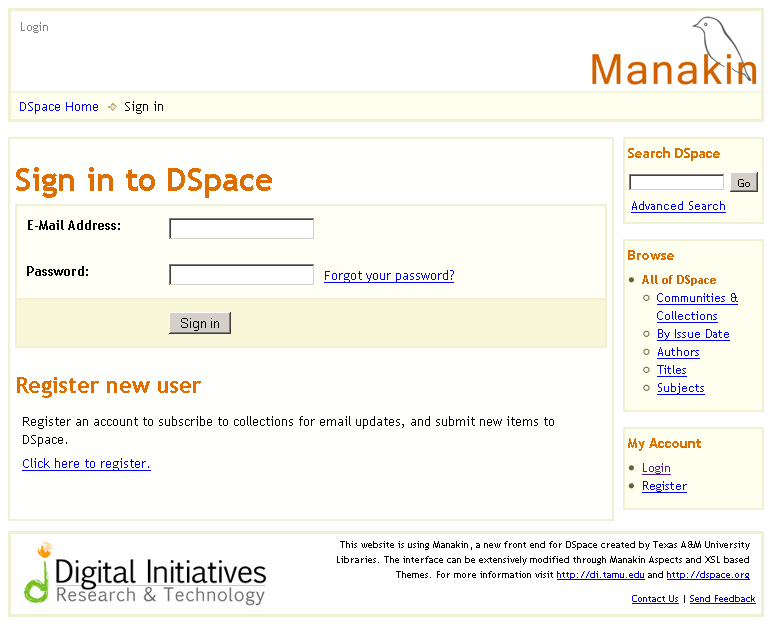 Ilustracja 3.
Ilustracja 3. Strona logowania
.
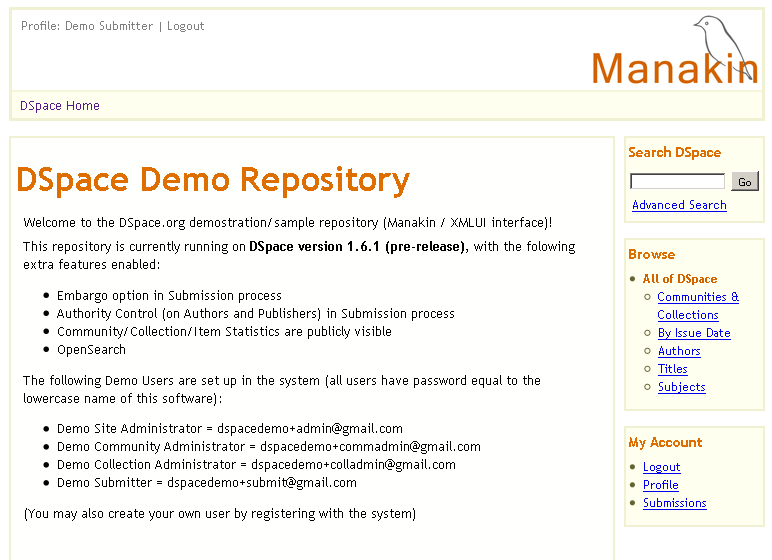 Ilustracja 4.
Ilustracja 4. Strona główna po zalogowaniu
.
Na stronie logowania (Ilustracja 3) należy wpisać adres mailowy oraz hasło
dspace i wcisnąć przycisk
Sign in (Zaloguj) i można rozpocząć proces dodawania nowego elementu klikając na link
Submissions w prawej części strony (Ilustracja 4).
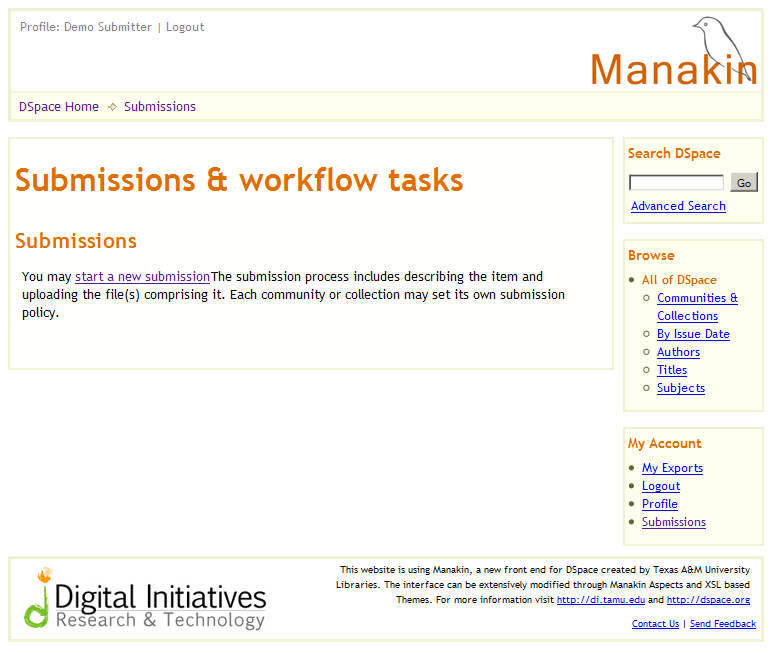 Ilustracja 5.
Ilustracja 5. Strona dodawania nowych pozycji z linkiem inicjującym.
Na stronie
Submissions & workflow tasks (Ilustracja 5) dodajemy nową pozycję klikając w link
Start a new submission.
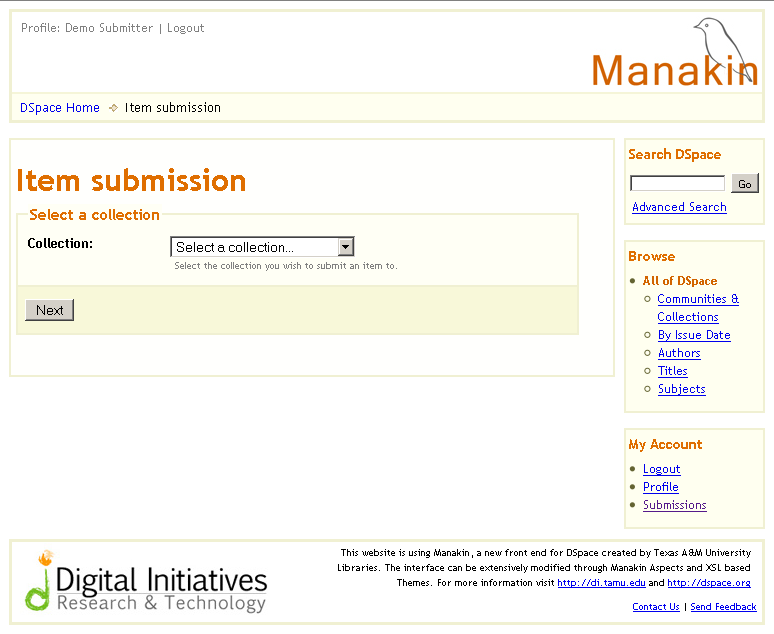 Ilustracja 6.
Ilustracja 6. Wybór kolekcji, do której dołączymy nowy element.
Przede wszystkim należy wybrać jedną z istniejących kolekcji do której chcemy dodać nową pozycję (Ilustracja 6). Na przykład, może to być
Collection of Sample Items (Kolekcja próbnych pozycji). Następnie należy wcisnąć przycisk
Next (Dalej). Od zakończenia procesu dzieli nas już tylko siedem prostych kroków. Na każdym etapie możemy się zatrzymać i wznowić naszą pracę później. Wszystkie dane, które wprowadzimy zostaną zapisane.
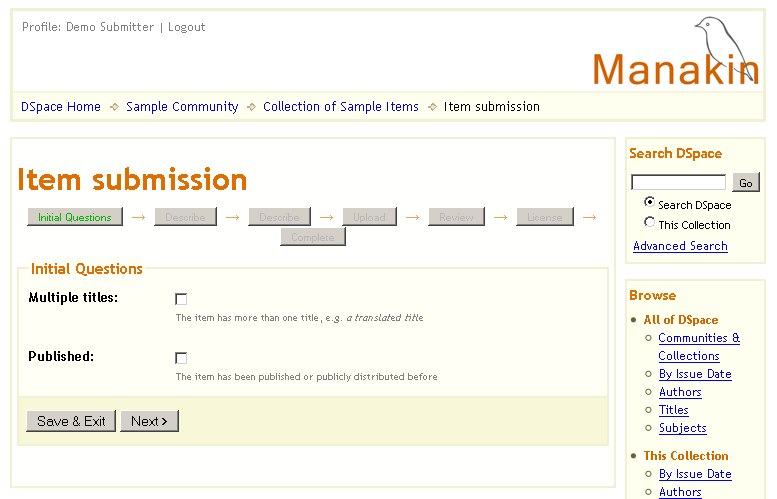 Ilustracja 7.
Ilustracja 7. Pytania wstępne.
Na początku mamy do wyboru dwa pola (Ilustracja 7):
- wiele tytułów - należy wybrać tę możliwość, jeśli element ma więcej niż jeden tytuł
- publikowane - wybieramy, jeśli element był publikowany lub dystrybuowany publicznie
Należy pozostawić te pola niezaznaczone i kliknąć przycisk
Next, aby przejść do następnego kroku.
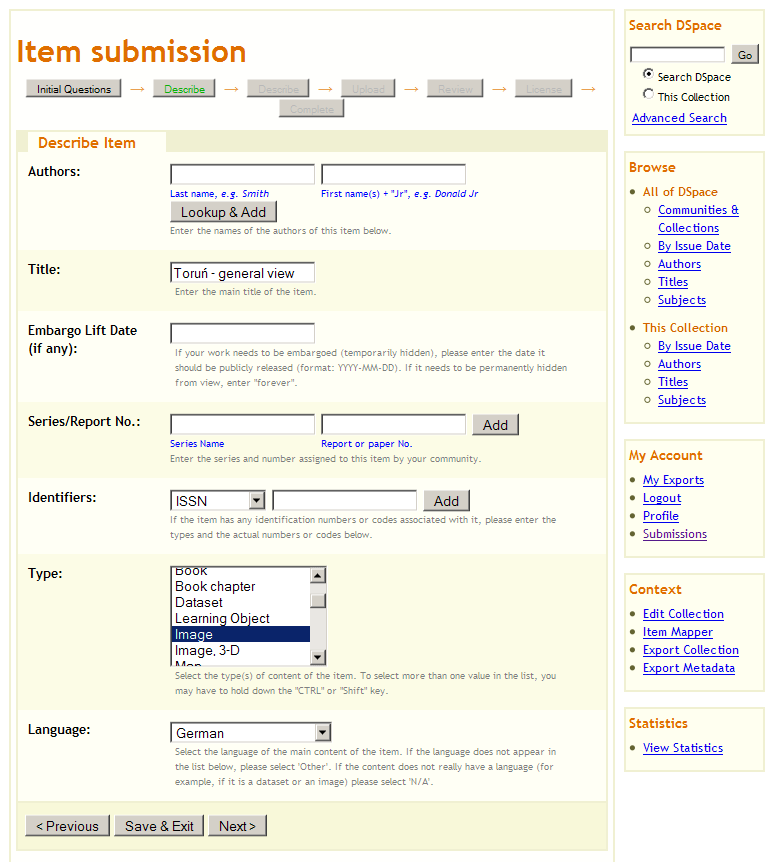 Ilustracja 8.
Ilustracja 8. Dodawanie metadanych do elementu.
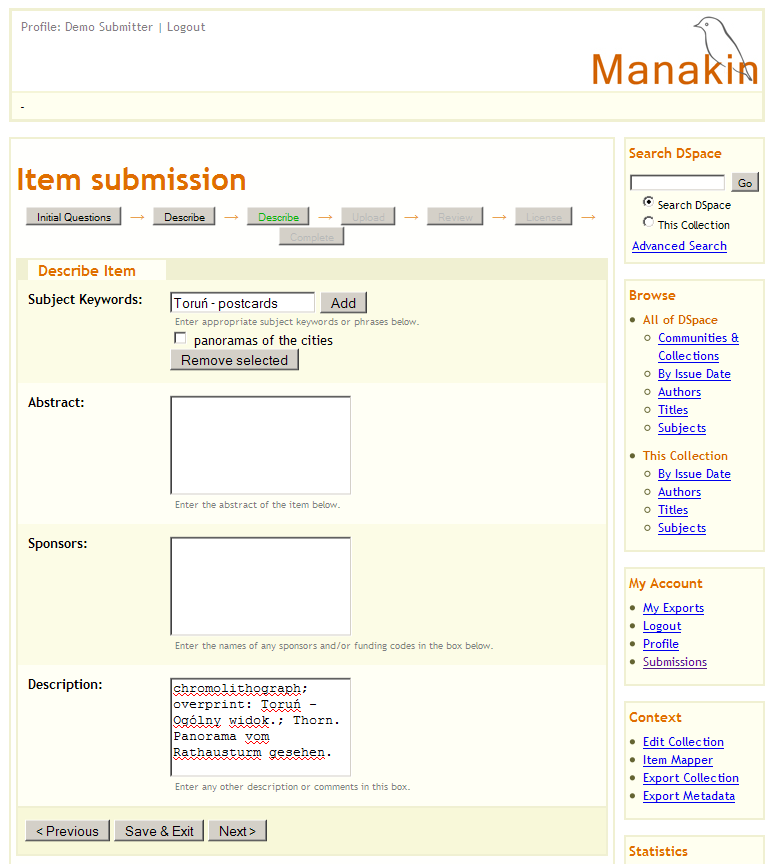 Ilustracja 9.
Ilustracja 9. Dodawanie metadanych do elementu.
Kolejne dwa kroki (przedstawione na ilustracjach 8 i 9) umożliwiają dodawanie przygotowanych wcześniej metadanych. W polu tytuł należy wprowadzić główny tytuł elementu. Na liście
Type selection (Wybór typu) należy wybrać typ elementu. W przypadku skanu karty pocztowej użytego w tym przykładzie należy wybrać
Image (Obraz). Oczywiście w innych przypadkach można wybrać inne typy. W liście rozwijalnej
Language (Język) należy wybrać język elementu. W polu
Subject Keywords wprowadzany słowa kluczowe, które dodajemy za pomocą przycisku
Add (Dodaj). Należy również wypełnić pole
Description (Opis). Pozostałe pola mogą zostać niewypełnione.
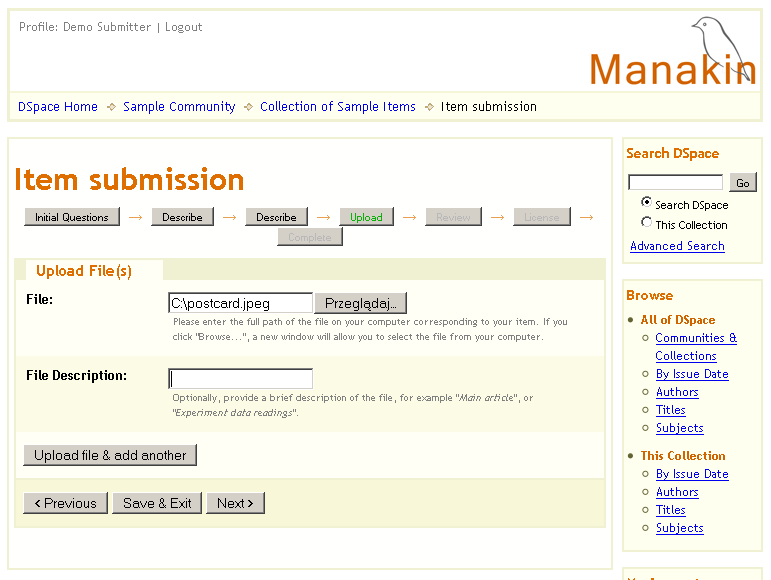 Ilustracja 10.
Ilustracja 10. Przesyłanie plików z opisem.
W sekcji
Upload (Przesyłanie) na ilustracji 10. należy wysłać obraz przedstawiający pocztówkę. W polu
File (Plik) wprowadzamy pełną ścieżkę dostępu do pliku na lokalnym komputerze. Można również kliknąć przycisk
Browse... (Przeglądaj) i wybrać plik, przeglądając system plików na komputerze. Po podaniu pełnej ścieżki do pliku można kliknąć
Upload file & add another (Prześlij i dodaj kolejny). Wybrany plik zostanie przesłany do repozytorium. Do kolejnego kroku przechodzi się po kliknięciu przycisku
Next.
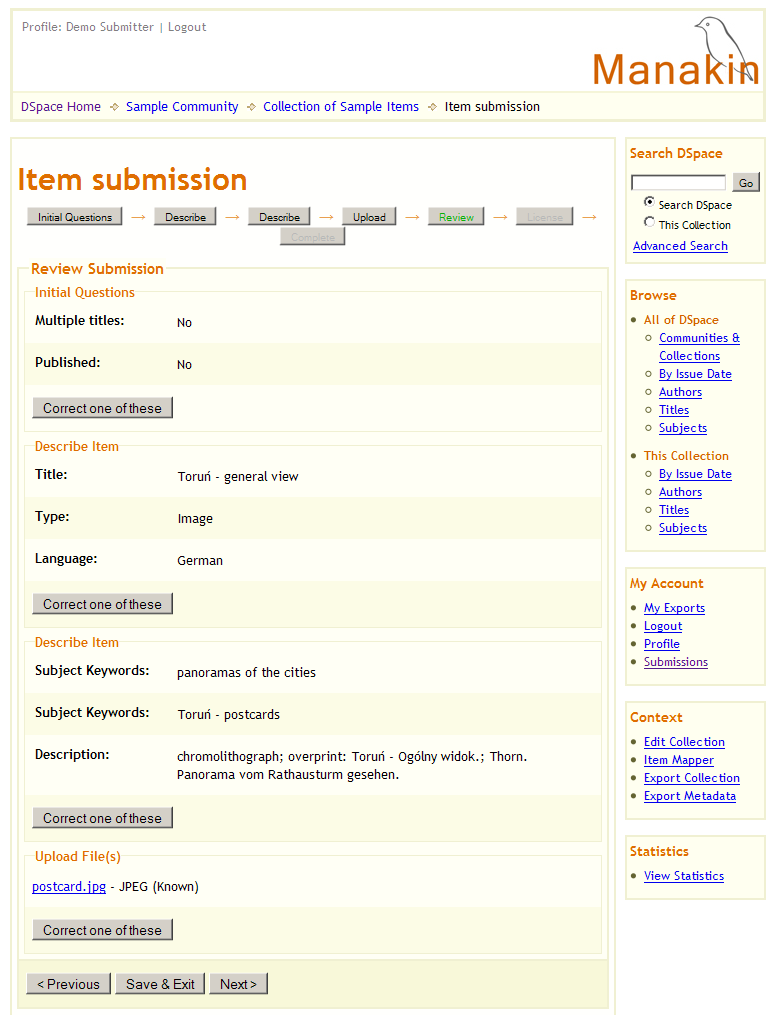 Ilustracja 11.
Ilustracja 11. Przegląd wszystkich kroków przesyłania elementu.
W kroku
Review (Przegląd) (ilustracja 11) można sprawdzić wszystkie wartości wprowadzone dotychczas. Jeśli zajdzie potrzeba dokonania korekty, należy użyć przycisku
Correct one of these (Popraw opis). Jeśli wszystko się zgadza, przechodzimy do następnego kroku klikając przycisk
Next.
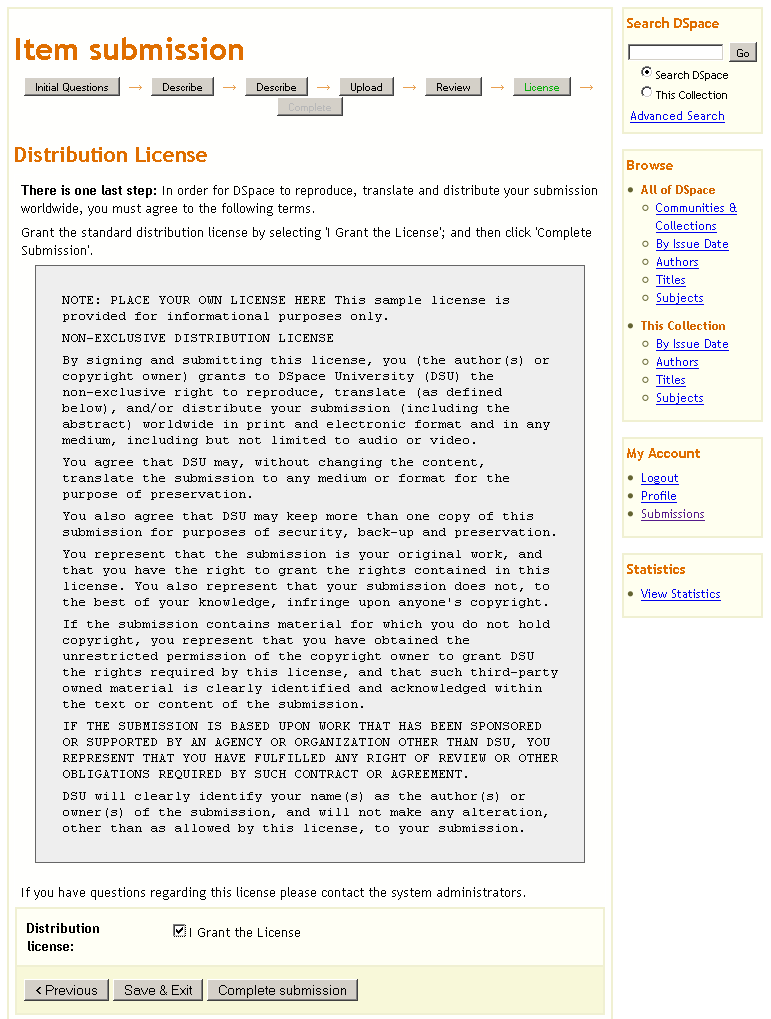 Ilustracja 12.
Ilustracja 12. Nadawania licencji do rozpowszechniania.
W ostatnim kroku, przez zaznaczenie pola
I grant the license (Udzielam licencji), nadaje się licencję do rozpowszechniania (ilustracja 12). Następnie należy kliknąć przycisk
Complete submission (Ukończ publikację). Publikacja elementu jest ukończona, teraz można odszukać nowo dodany element w demonstracyjnej wersji repozytorium.
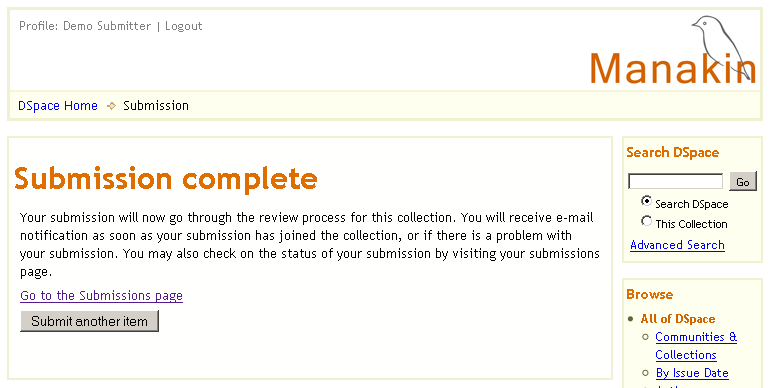 Ilustracja 13.
Ilustracja 13. Ukończenie publikacji elementu.
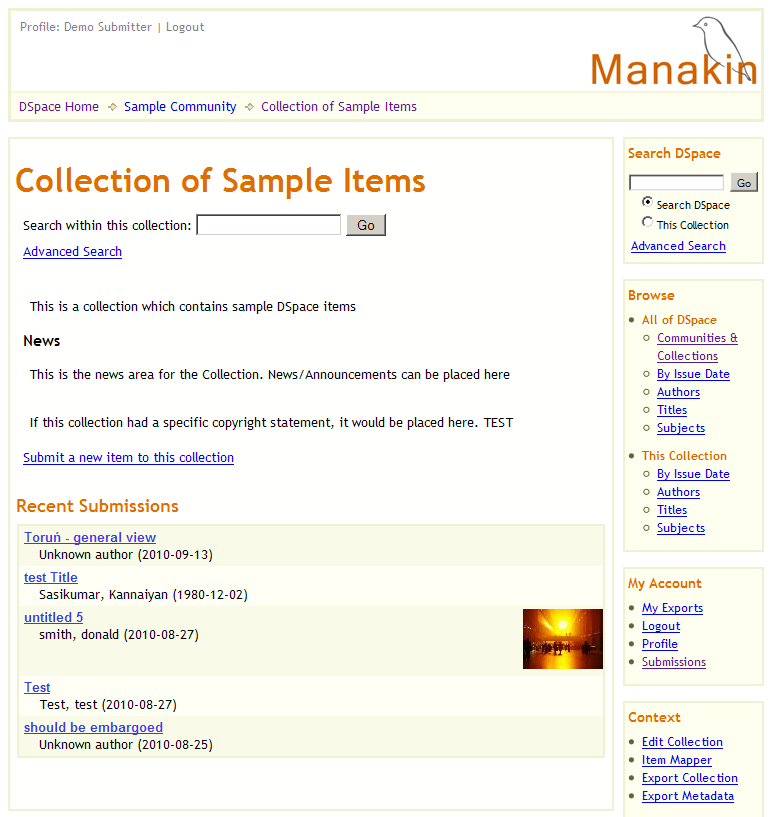 Ilustracja 14.
Ilustracja 14. Ostatnio dodane elementy w przykładowej kolekcji.
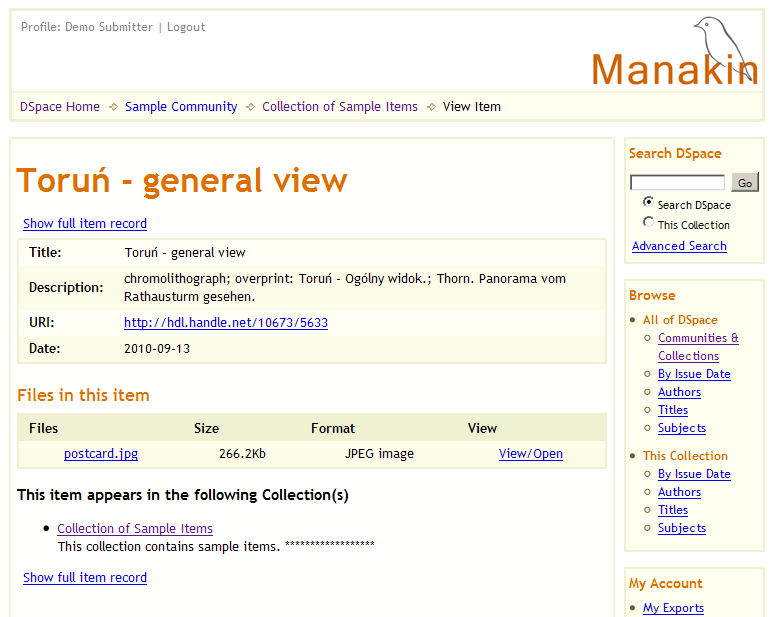 Ilustracja 15.
Ilustracja 15. Nowo utworzone elementy dostępne w demonstracyjnej wersji repozytorium.
W menu
Browse (Przeglądaj) po prawej stronie (ilustracja 13) należy kliknąć
Communities & Collections (Społeczności i Kolekcje). Na długiej liście społeczności i kolekcji należy znaleźć kolekcję
Collection of Sample Items i kliknąć w nią. Jest to kolekcja, którą wybraliśmy na początku procesu publikacji elementu. Na stronie wybranej kolekcji znajduje się lista ostatnio opublikowanych elementów (ilustracja 14). Należy teraz kliknąć na
Toruń – general view aby obejrzeć element, który właśnie został opublikowany (ilustracja 15). System automatycznie dodaje niektóre metadane do obiektu. Po kliknięciu w
Show full item record (Pokaż pełny rekord elementu) ukaże się pełen opis. Oprócz wartości dodanych ręcznie, będą tam też wartości atrybutów dc.date.accessioned, dc.date.available, dc.date.issued i dc.identifier.uri.
Publikowanie obiektu cyfrowego w systemie Greenstone
Aby opublikować obiekt cyfrowy w systemie Greenstone, należy użyć interfejsu bibliotekarskiego Greenstone. Jest to aplikacja, którą instaluje się na lokalnym komputerze. Na proces publikacji obiektów cyfrowych składają się następujące działania:
- wybór istniejącej kolekcji lub stworzenie nowej
- wybór plików do dodania do kolekcji
- wzbogacenie plików metadanymi
- tworzenie lub zmiana kolekcji.
Najprostszym sposobem na wypróbowanie interfejsu bibliotekarskiego jest zainstalowanie oprogramowania Greenstone na komputerze. Można go pobrać ze
strony pobierana Greenstone. W zależności od posiadanego systemu operacyjnego należy wybrać wersję dla Windows, MacOS lub Linux/Unix. W trakcie pisania tego kompendium ostatnią wersją była 2.83. Instalacja jest prosta i nie powinna zabrać dużo czasu. Więcej informacji znajduje się w
Przewodniku po instalacji (tekst w języku angielskim) na stronie
Greenstone Wiki.
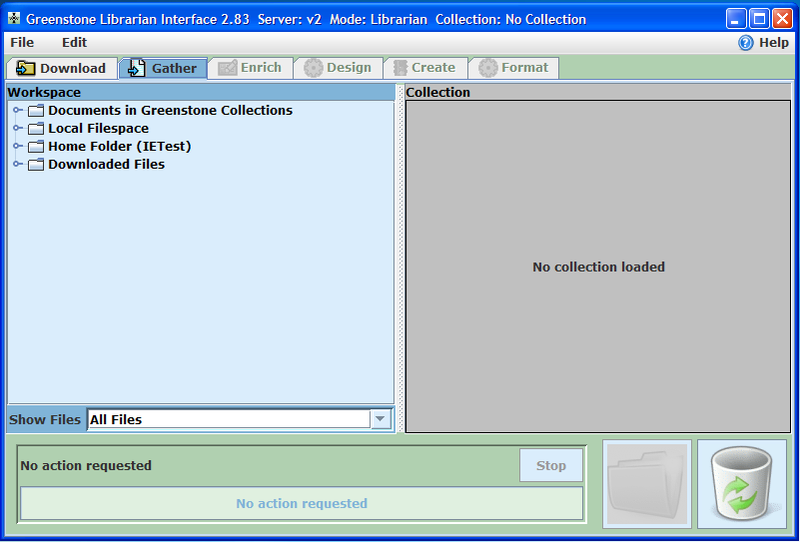 Ilustracja 16.
Ilustracja 16. Interfejs bibliotekarski Greenstone
.
Załóżmy, że mamy już na komputerze zainstalowany program Greenstone. Interfejs bibliotekarski uruchamiamy wybierając
Librarian Interface (GLI) z menu
Start/Programs/Greenstone-2.83 w systemie operacyjnym Windows. W Linuksie lub innych systemach Unixowych należy uruchomić skrypt
gli.sh zlokalizowany w folderze
gsdl.
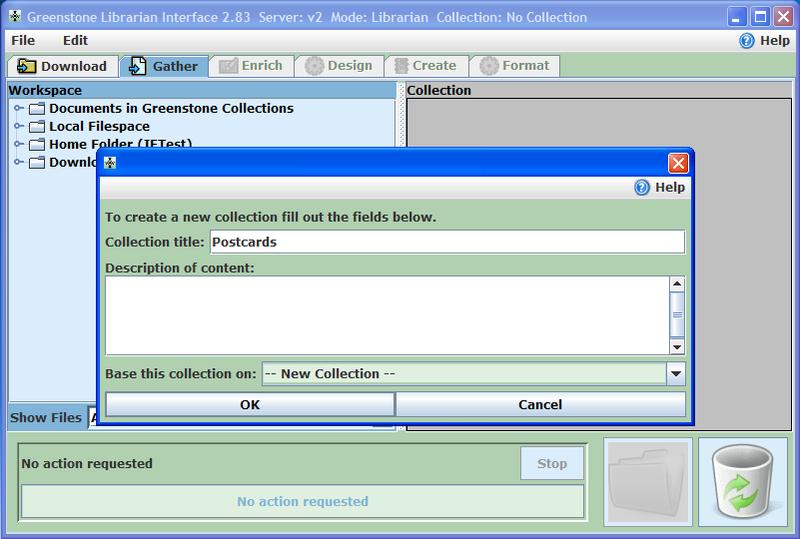 Ilustracja 17.
Ilustracja 17. Tworzenie nowej kolekcji.
W bibliotece cyfrowej Greenstone obiekty cyfrowe są organizowane w kolekcjach. Należy zacząć działanie od otworzenia istniejącej kolekcję lub stworzenia nowej. Aby rozpocząć pracę z nową kolekcją należy użyć opcji
New... z menu
Plik i wprowadzić standardowe informacje: tytuł kolekcji oraz opis zawartości. Jak można dostrzec na ilustracji 17., należy podać na której kolekcji będzie bazowała nowo utworzona. Następnie należy wybrać opcję
New collection, aby stworzyć całkiem nową kolekcję z domyślnymi ustawieniami. Aby potwierdzić utworzenie nowej kolekcji wybieramy przycisk
OK.
 Ilustracja 18.
Ilustracja 18. Dodawanie plików do kolekcji
.
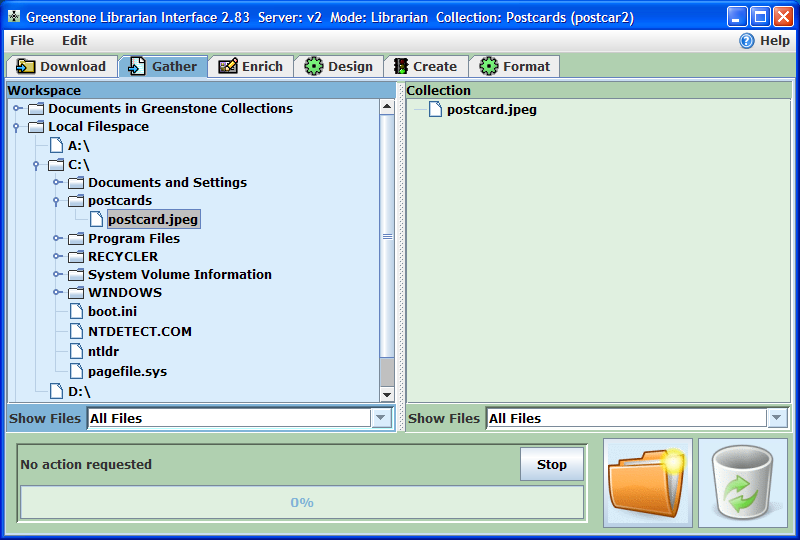
Na tym etapie należy wybrać pliki do nowej kolekcji. Aby to zrobić należy posłużyć się zakładką
Gather (Utwórz zbiór) pokazaną na ilustracji 18. Panel ten jest podzielony na dwie części. Po lewej stronie znajduje się panel przestrzeni roboczej, który pozwala na przeglądanie sytemu plików na komputerze. Przeglądanie plików można zacząć od konkretnego dysku lub folderu użytkownika. Aby ułatwić przeglądanie plików można filtrować wyniki widoczne w drzewie plików, przy użyciu listy rozwijalnej
Show Files (Pokaż pliki). Następnie należy zlokalizować plik z pocztówką. W naszym przykładzie będzie to plik z folderu postcard na dysku C. Po prawej stronie znajduje się panel
Collection (Kolekcje), gdzie należy umieścić pliki, które powinny się znaleźć w kolekcji. Najprostsza metoda to przeciągnięcie pliku z lewego panelu do prawego.
 Ilustracja 19.
Ilustracja 19. Dodawanie metadanych do plików
.
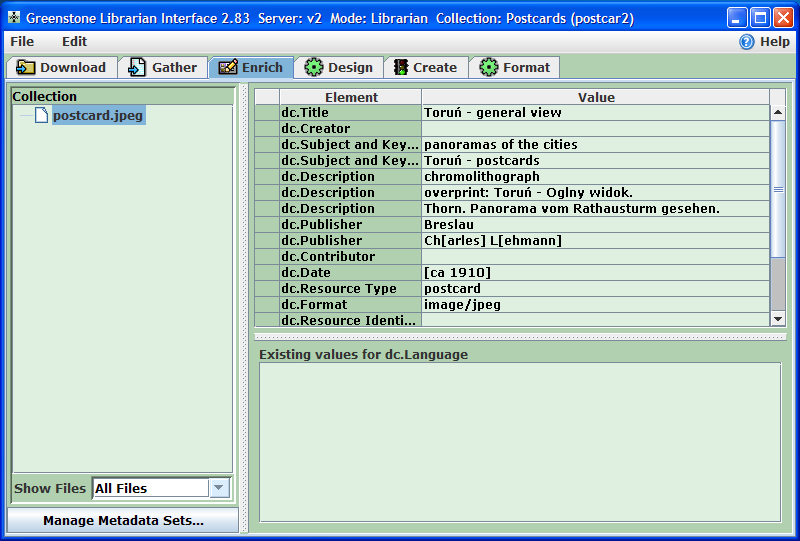
Teraz można przejść do kolejnego etapu, w którym wzbogacimy pliki metadanymi. Aby to zrobić należy kliknąć na zakładkę
Enrich (Dodaj metadane). Po lewej stronie panelu znajduje się drzewo plików z kolekcji. W naszym przykładzie znajduje się tylko jeden plik (ilustracja 19), ale z biegiem czasu ilość elementów w kolekcji będzie się powiększać, a wtedy może okazać się przydatne filtrowanie plików. Dzięki liście
Show files (Pokaż pliki), zlokalizowanej pod drzewem kolekcji, można wskazać pliki tylko jednego rodzaju, np. obrazy, strony HTML, dokumenty biurowe, pliki PDF.
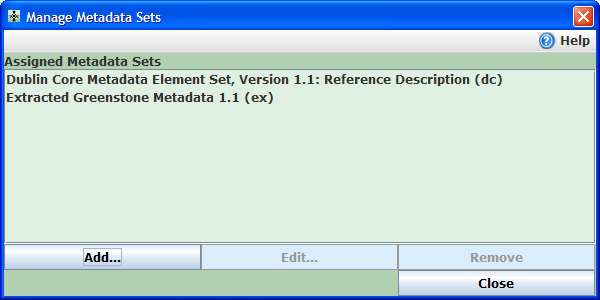
Przed rozpoczęciem dodawania metadanych do pliku, należy sprawdzić, który schemat metadanych może być użyty w tym celu. W związku z tym należy kliknąć na przycisk
Manage Metadata Sets (Zarządzaj zestawami metadanych), który znajduje się w lewym dolnym rogu panelu
Enrich (Wzbogać) i wyświetlić okno z listą metadanych przypisanych do kolekcji. Nowe kolekcje mają przypisane domyślnie dwa zestawy metadanych. Użytkownik może użyć do opisu plików 15 atrybutów Dublin Core Metadata Element Set (wersja 1.1). Wyekstrahowane metadane systemu Greenstone są używane do przechowywania takich informacji na temat plików, jak: nazwa pliku, format pliku, rozdzielczość pliku i tym podobne. Wartości tych atrybutów są generowane w procesie budowania kolekcji nie mogą być edytowane ręcznie.
 Ilustracja 20.
Ilustracja 20. Domyślne ustawienia metadanych
.
Aby dodać metadane do obrazu pocztówki należy zaznaczyć plik z listy drzewa kolekcji i wprowadzić wartości atrybutów w tabeli po prawej stronie panelu. Po dodaniu wszystkich metadanych klikamy na zakładkę
Create (Utwórz).
 Ilustracja 21
Ilustracja 21. Tworzenie nowej kolekcji.
 Ilustracja 22.
Ilustracja 22. Utworzona kolekcja
.
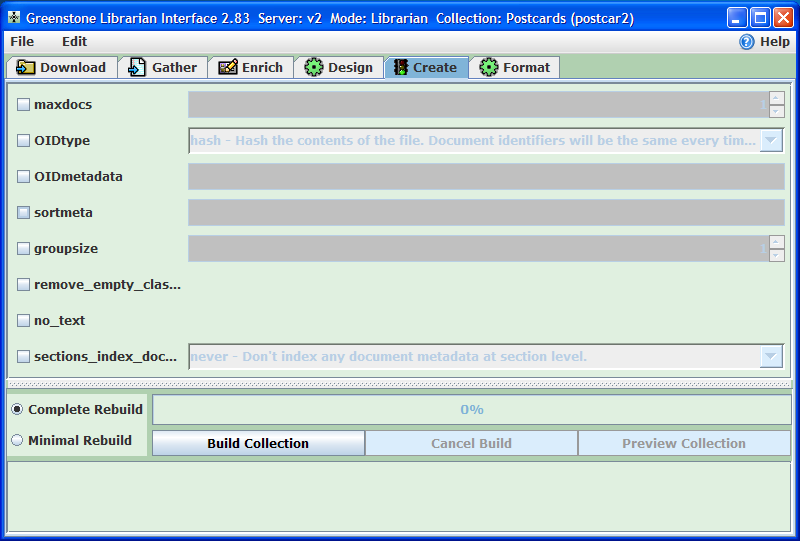
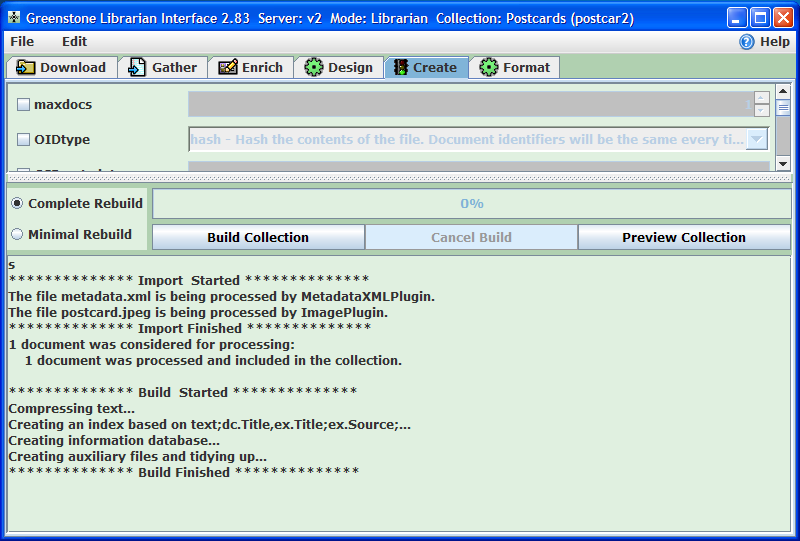
W tej części pokazane jest tworzenie kolekcji zawierających pliki i metadane zdefiniowane w poprzednich częściach lekcji. Budowę kolekcji należy zacząć od przycisku
Build collection (Utwórz kolekcję) (ilustracja 21). Pasek postępu działań nad przyciskiem
Build Collection wskazuje stopień wykonania tego zadania, zaś dodatkowe informacje pojawiające się u dołu są bardziej szczegółowe.
 Ilustracja 23.
Ilustracja 23. Podgląd kolekcji.
 Ilustracja 24.
Ilustracja 24. Nowy rekord w indeksie tytułów
.
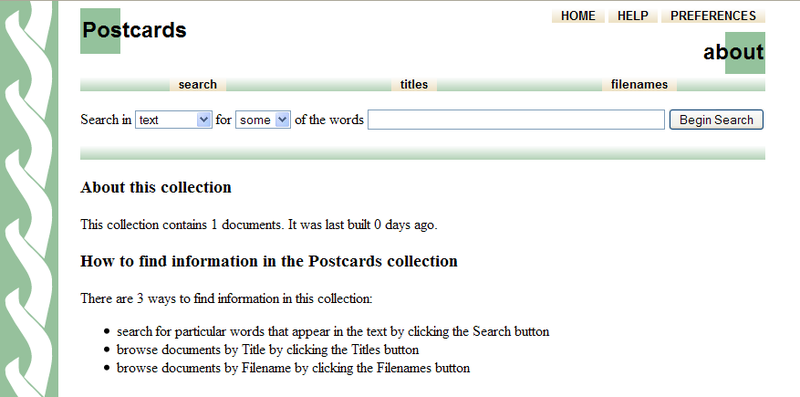
Po zakończeniu tworzenia kolekcji, aktywny staje się przycisk
Preview Collection (podgląd kolekcji). Klikając na ten przycisk, uruchamiamy przeglądarkę ze stroną nowej kolekcji (ilustracja 23). Aby znaleźć obiekt, który został dopiero dodany do biblioteki cyfrowej Greenstone należy użyć opcji szukaj lub skorzystać z indeksów. Aby otworzyć indeks tytułów należy kliknąć na link tytuły u góry strony. Natomiast klikając w miniaturkę obrazka można otworzyć jego plik (ilustracja 24).
Publikowanie obiektu cyfrowego w systemie dLibra
Publikowanie obiektów cyfrowych w systemie dLibra jest obsługiwane przez aplikację redaktora. Cyfrowy obiekt w tym systemie nazywany jest publikacją. Proces tworzenia publikacji z reguły składa się z następujących działań:
- wyboru pliku do publikacji
- zaimportowania lub przypisania metadanych
- ustawienia zakresu praw użytkowników do publikacji
- dodania publikacji do kolekcji
- dodania informacji na stronę WWW, takich jak opis, komentarz i miniatura
- wprowadzenia informacji ogólnych i ustawień publikacji
- przesłania plików składających się na publikację na serwer.
W lekcji niniejszej zostanie pokazany sposób uruchomienia edytora, utworzenia publikacji i przejrzenia rezultatów tego procesu.
W naszym przykładzie wykorzystana została testowa wersja systemu dLibra dostępna na stronie
http://dlab.psnc.pl/dlibra/demo/. W celu użycia edytora tej wersji testowej należy stworzyć odpowiednie konto użytkownika. Aby to zrobić należy wysłać wiadomość na adres
dlibra@psnc.pl.
Uruchomienie edytora
Edytor uruchamiamy wpisując adres http://demo.dl.psnc.pl/jnlp/w przeglądarce. W ten sposób ściągniemy i uruchomimy aplikację redaktora, wymaga ona zainstalowania w systemie środowiska uruchomieniowego Java.
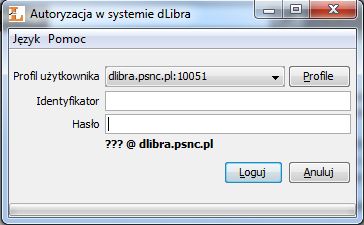
Ilustracja 25. Okno logowania.
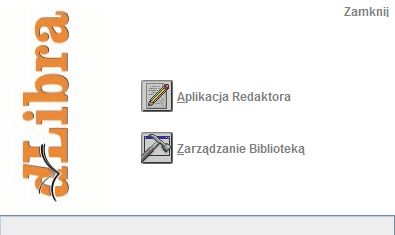 Ilustracja 26.
Ilustracja 26. Wybór aplikacji.
Następnie należy wprowadzić dane w oknie pokazanym na Ilustracji 25. podając nazwę użytkownika i hasło. Dalej należy kliknąc na przycisk
Loguj. Po pomyślnej weryfikacji danych użytkownika, wyświetlone zostanie małe okienko, pozwalające na wybór jednej z dwóch aplikacji. Należy wówczas wybrać ikonkę
Aplikacja redaktora i poczekać na otwarcie się głównego okna aplikacji. Aplikacja
Zarządanie Biblioteką pozwala realizować czynności administracyjne takie jak zmiana schematu metadanych biblioteki, dodawanie/usuwanie użytkowników itp.
Tworzenie publikacji
Można teraz zacząć tworzyć nową przykładową publikację.
 Ilustracja 27.
Ilustracja 27. Okno główne przeglądarki publikacji
.
W tym celu klikamy na ikonę
Nowa publikacja znajdującą się na głównym pasku (Ilustracja 27.) lub wybieramy pozycję
Nowa publikacja z menu
Zarządzanie. W ten sposób zostanie uruchomiony kreator nowych publikacji. Wykorzystanie kreatora do publikacji składa się z siedmiu kroków pokazanych na ilustracjach 4 do 11.
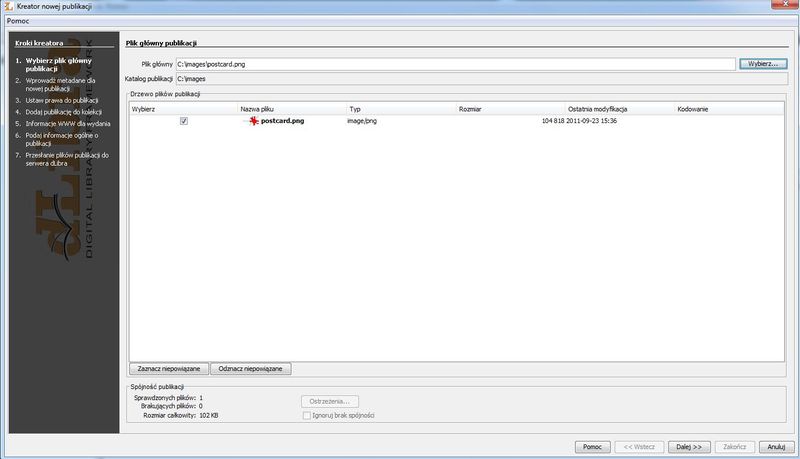 Ilustracja 28.
Ilustracja 28. Wybór głównego pliku do publikacji.
Pierwsze działanie to wybór głównego pliku do publikacji. Należy kliknąć przycisk
Wybierz i przeglądając system plików odnaleźć wybrany przez nas wcześniej plik widokówki. W naszym przykładzie znajduje się on w lokalizacji c:\images\postcard.jpeg. Po odnalezieniu pliku na dysku, należy go zaznaczyć i kliknąć
OK lub kliknąć go podwójnie. Plik jest teraz widoczny w drzewie plików do publikacji (Ilustracja 28). Nasza publikacja składa się tylko z jednego pliku. Możemy teraz przejść do kolejnego etapu, klikając przycisk
Dalej.
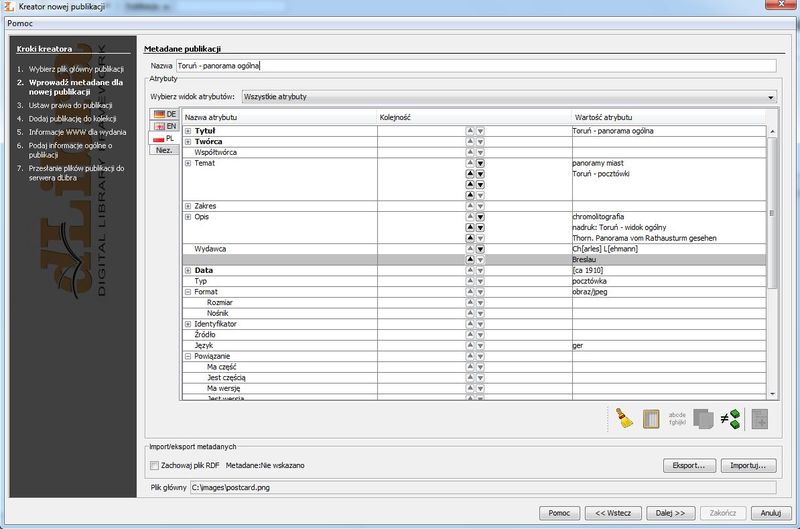 Ilustracja 29.
Ilustracja 29. Metadane nowej publikacji.
W drugim etapie należy wprowadzić metadane publikacji (Ilustracja 29). W tabeli atrybutów należy wprowadzić wcześniej przygotowane wartości dla metadanych. Nie należy wprowadzać wartości atrybutu Format, gdyż edytor dodaje tę wartość automatycznie na podstawie formatu pliku. Nazwa publikacji jest tworzona automatycznie w oparciu o tytuł, autora i datę utworzenia zawarte w metadanych. Po zakończeniu pracy nad tworzeniem opisu możemy przejść do następnego etapu w kreatorze.
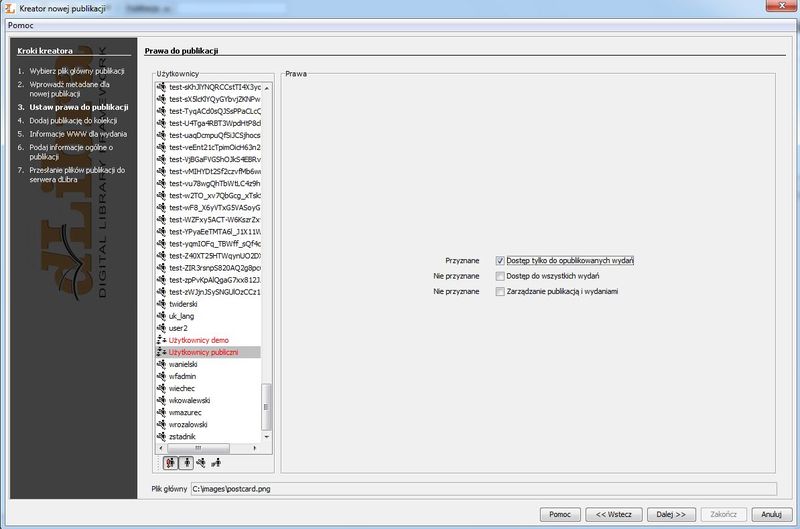 Ilustracja 30.
Ilustracja 30. Prawa do publikacji.
Trzeci etap ukazany na Ilustracji 30. umożliwia ustalenie praw do przeglądania publikacji. Wybieramy pozycję Użytkownicy publiczni z listy użytkowników i zaznaczamy pozycję Podgląd po prawej stronie. Następnie naciskamy przycisk Dalej, aby przejść cod kolejnego etapu.
 Ilustracja 31.
Ilustracja 31. Wybór kolekcji.
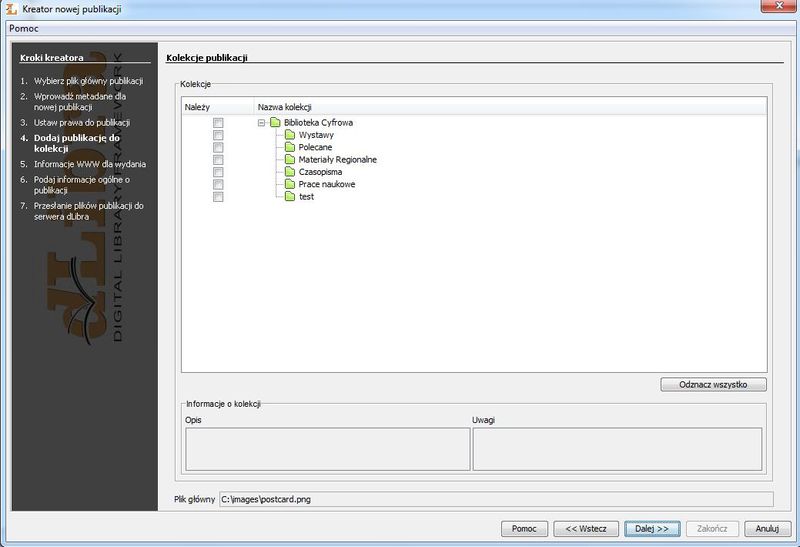
Na stronie
Kolekcje publikacji (ilustracja 31) wybieramy co najmniej jedną kolekcję z drzewa kolekcji. Publikacja ta zostanie przydzielona do zaznaczonych kolekcji. Przechodzimy do następnego etapu.
 Ilustracja 32.
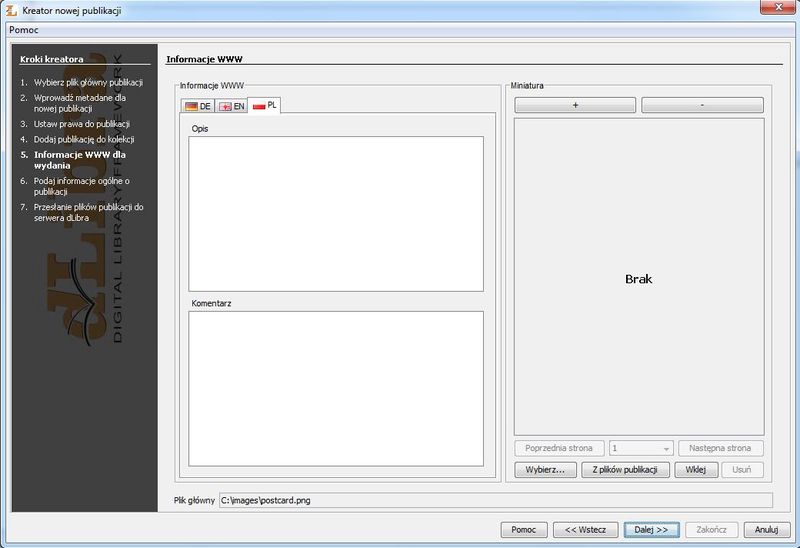
Ilustracja 32. Edycja informacji na stronę WWW.
W piątym etapie (ilustracja 32) wykorzystania kreatora mamy możliwość dodania opisu, komentarza i miniatury do publikacji. Rola tych pól zależy od konwencji przyjętych w danej bibliotece cyfrowej. Zawartość pola opis nie jest widoczna dla zwykłych użytkowników może więc zawierać ono informacje np. na temat samego procesu digitalizacji. Aby przejść do kolejnego etapu klikamy
Dalej.
 Ilustracja 33.
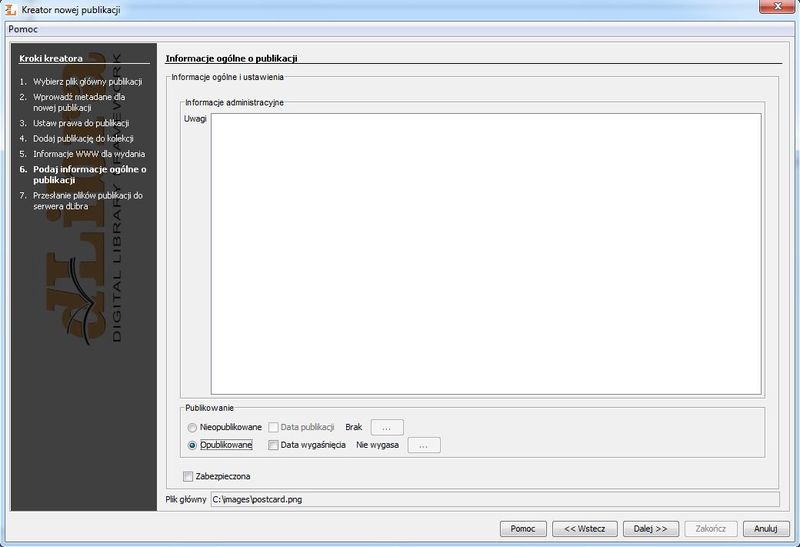
Ilustracja 33. Publikowanie informacji ogólnych.
Na stronie Publikowanie informacji ogólnych widocznej na ilustracji 33. sprawdzamy opcję Opublikowane w ramce Pierwsza edycja. Bez zaznaczenia tej opcji, publikacja nie będzie widoczna dla użytkowników w bibliotece cyfrowej. Dodatkowo można ustawić datę ważności danej publikacji i wówczas w wyznaczonym dniu przestanie ona być widoczna dla użytkowników. Co więcej publikacja może zostać zabezpieczona - zależnie od formatu pliku - aby opcja kopiowania i drukowania były niedostępne. Naciskamy teraz przycisk Dalej, aby przejść do kolejnej strony.
 Ilustracja 34.
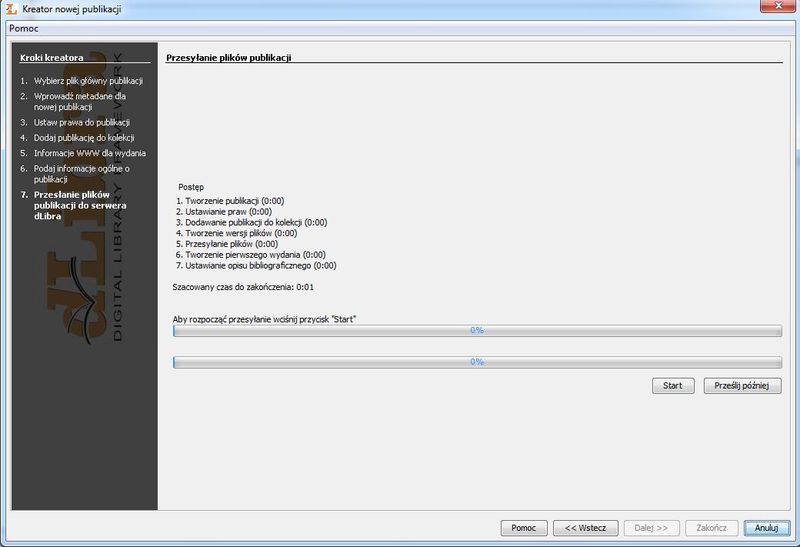
Ilustracja 34. Przesyłanie plików do opublikowania.
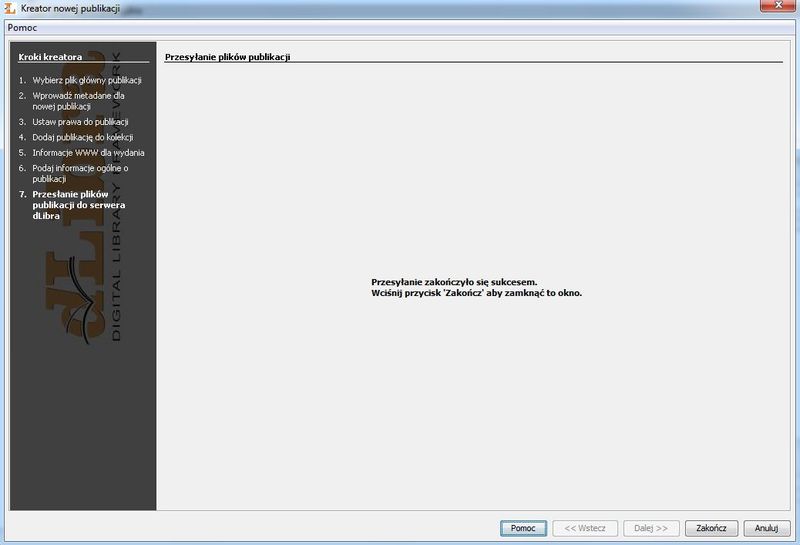 Ilustracja 35
Ilustracja 35. Zakończenie
.
Na koniec stworzona zostanie publikacja, a następnie przesłana na serwer biblioteki cyfrowej. Naciskamy przycisk
Start i czekamy na utworzenie publikacji (ilustracja 35). Powinno to potrwać kilka sekund. Kiedy publikacja zostanie utworzona, wyświetli się odpowiednia informacja. Naciskamy wówczas przycisk
Zakończ. Publikacja została utworzona i można zobaczyć jej rezultaty on-line.
Przegladanie rezultatów on-line
Aby obejrzeć zasób przechodzimy na stronę WWW biblioteki cyfrowej. W prezentowanych powyżej przykładach
Aplikacja redaktora operowała na demonstracyjnej instancji dLibry. Poniżej prezentujemy jak wygląda przykładowy obiekt w Kujawsko-Pomorskiej Bibliotece Cyfrowej z której pochodzi.
Ilustracja 36. Przeglądanie publikacji on-line.
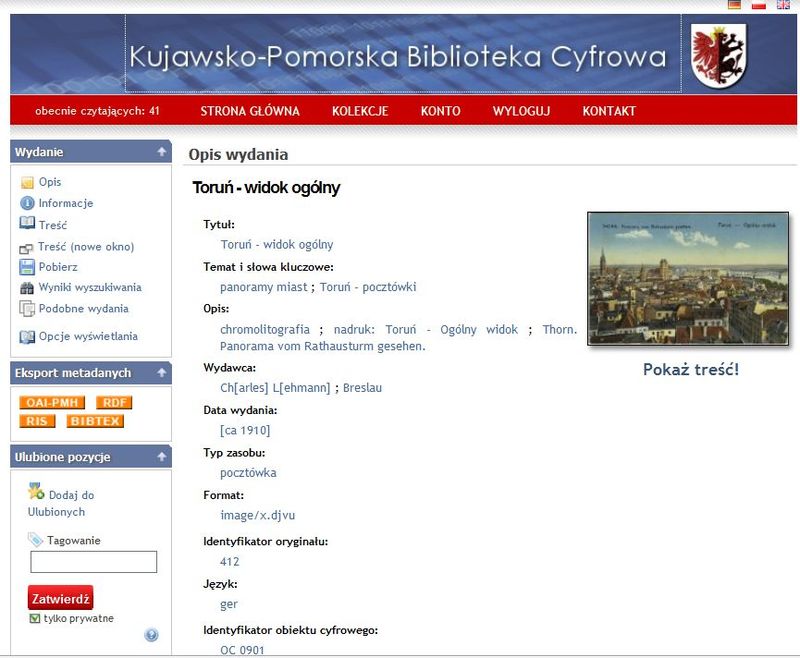
Ilustracja 37. Przeglądanie opisu publikacji.
 Ilustracja 38.
Ilustracja 38. Przeglądanie publikacji on-line.
W jaki sposób promować obiekty cyfrowe w Internecie?
Jaki jest cel promowania obiektów cyfrowych?
Przedstawione już zostały informacje jak może wyglądać proces digitalizacji. Czytelnik kompendium został już zapoznany z wszystkimi etapami organizacji pracy: wyborem obiektów do digitalizacji, przygotowaniem metadanych obiektów, wyborem właściwego sprzętu do przeprowadzenia digitalizacji, skanowaniem danych obiektów, korektą powstałych w wyniku skanowania obrazów za pomocą oprogramowania graficznego, przygotowaniem wersji obiektu cyfrowego do publikacji w sieci, utworzeniem cyfrowej kopii głównej i opublikowaniem obiektu w bibliotece cyfrowej. W związku z tym jest już przygotowany do utworzenia biblioteki cyfrowej w swojej macierzystej instytucji, wykonując wszystkie prace samodzielnie lub zlecając to instytucji zewnętrznej. Czy wykonanie wszystkich zadań oznacza, że cel został osiągnięty? Jeśli cały proces przebiegał prawidłowo, można być pewnym, że kolekcje zostaną zachowane w formacie cyfrowym dla przyszłości. Dzięki połączeniu OCR z możliwościami oprogramowania do tworzenia bibliotek cyfrowych, będę mogły być wyszukiwane obiekty. Ale może się zdarzyć, że żaden inny cel nie zostanie osiągnięty, ponieważ nikt nie uzyska dostępu do zasobów, które będą udostępnione. Może być wiele powodów takiego stanu rzeczy:
- użytkownik, który nie ma świadomości istnienia zasobów, nigdy ich nie odnajdzie w Internecie,
- użytkownik, który wie, że interesujące go zasoby są gdzieś dostępne, nie będzie w stanie odnaleźć tych zasobów (jeśli nie można znaleźć czegoś w Google, to dana rzecz nie istnieje),
- użytkownik, który trafi do strony internetowej biblioteki cyfrowej nie będzie w stanie odnaleźć lub odczytać zlokalizowanych w tym miejscu zasobów.
W związku z powyższym, wykonanie wszystkich etapów procesu digitalizacji, nawet w najlepszy sposób, nie gwarantuje osiągnięcia zamierzonych rezultatów. Czego zatem potrzebujemy? Powinniśmy adekwatnie promować rezultaty naszej pracy.
Obiekty cyfrowe i biblioteka cyfrowa powinny być traktowane jako produkt (w znaczeniu marketingowym) i być promowane zgodnie ze strategiami marketingowymi. Nie musi oznaczać to bardzo dużych kosztów. Biblioteka to instytucja non-profit i w związku z tym powinna używać tzw. marketingu społecznego. Podstawowa reguła, jaka powinna przyświecać promocji biblioteki to unikanie natarczywości. Odbiorcy nie oczekują agresywnej reklamy w telewizji i na przydrożnych bilbordach. Zamiast tego potrzebują rzetelnej informacji jak dotrzeć do obiektów cyfrowych i jak z nich korzystać. Co więcej, idealnym sposobem promocji biblioteki cyfrowej jest marketing internetowy, który jest nie tylko tani i efektywny, ale także nieinwazyjny.
Promocja biblioteki cyfrowej
Promocję obiektów cyfrowych można rozpocząć pośrednio dzięki promocji biblioteki cyfrowej, w której są one dostępne. Dzięki temu użytkownik, który odwiedzi bibliotekę cyfrową, będzie blisko obiektów cyfrowych. W tej sekcji przedstawione są metody promowania biblioteki cyfrowej.
Strona internetowa jest tą częścią biblioteki cyfrowej, z którą użytkownicy mają najczęściej do czynienia. Z tego powodu ważna jest dbałość o wysoką jakość tego elementu. Zgodnie z badaniami przeprowadzonymi przez J. Nielsena: "Ludzie rzadko czytają strony internetowe słowo po słowie; zamiast tego przeglądają stronę, wybierając indywidualne wyrazy lub zdania". 79 procent pytanych użytkowników zawsze przeglądało każdą nowa stronę, na którą wchodzili, jedynie 16 procent czytało je słowo po słowie. Oznacza to, że użytkownicy pomijają znaczną część strony internetowej. W pierwszej fazie kontaktu strona internetowa może wpływać na użytkownika szatą graficzna i układem. W kolejnej fazie użytkownik zapoznaje się ze sposobem poruszania się po stronie i zdobywania informacji. Ostatnią fazą zapoznawania się ze strona internetową jest kontakt z jej zawartością. Widać stąd jak istotne jest znaczenie dwóch pierwszych faz, które wpływają na proces dotarcia do informacji.
Z tego powodu należy przywiązywać dużą wagę do nawigacji witryny i atrakcyjnej prezentacji ważnej zawartości. Strona internetowa biblioteki cyfrowej powinna być ascetyczna. W związku z tym, że pełni głównie informacyjne i edukacyjne funkcje, niewskazane jest używanie rażących kolorów, grafiki i animacji, które mogą rozpraszać użytkownika.
W celu przyciągnięcia uwagi, strona internetowa powinna spełniać poniższe wymagania:
- wysoka pozycja w wynikach wyszukiwarek internetowych
- elementy, które zachęcają użytkownika do codziennych odwiedzin strony
- nagroda za wypełnienie ankiety
- nagrody cyfrowe (wygaszacz ekranu, tapeta)
- strona główna w języku angielskim.
Promocja biblioteki cyfrowej - SEO
Jedną z form marketingu internetowego jest marketing w wyszukiwarkach (search engine marketing, SEM), który zakłada promocję stron internetowych poprzez zwiększanie ich widoczności na stronach z wynikami wyszukiwarek internetowych dzięki zastosowaniu optymalizacji pod kątem wyszukiwarek, płatnego lokowania wyników wyszukiwania, reklamie kontekstowej oraz płatnemu zamieszczaniu ogłoszeń. Pozycjonowanie (search engine optimization, SEO) jest darmowym działaniem służącym zwiększaniu liczby odwiedzin witryny, przekierowywanych z wyszukiwarek internetowych. Optymalizacja strony internetowej zakłada po pierwsze edycję zawartości i kodu HTML, celem lepszego powiązania ze słowami kluczowymi i usunięcia barier w zakresie indeksowania przez wyszukiwarki internetowe. Jest to bardzo efektywna metoda promocji stron internetowych, która w znaczącym stopniu wpływa na ilość odwiedzin witryny, zarówno w sensie liczbowym, jak i jakościowym. Istnieje wiele firm świadczących usługi optymalizacji, ale są one zwykle zbyt kosztowne dla przeciętnej organizacji non profit. Można jednak zacząć optymalizację strony samodzielnie. Zacznijmy od przyjrzenia się nagłówkowi strony HTML. Zawiera on kilka istotnych sekcji, które obejmują:
- title - tytuł dokumentu przeznaczony dla przeglądarki
- meta name="description" - opis strony dla wyszukiwarek
- meta name="keywords" - słowa kluczowe wykorzystywane przez wyszukiwarki do odnalezienia strony internetowej
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta http-equiv="Content-Language" content="en" />
<title>Example Digital Library - Main page </title>
<meta name="Description" content="dLibra - digital libraries - system to create and manage digital library" />
<meta name="Keywords" content="dLibra, digital library" />
Ilustracja 39. Przykład nagłowka HTML.W przypadku niektórych stron w bibliotece cyfrowej możliwe jest automatyczne tworzenie tytułu i meta-opisu. Zależy to od oprogramowania, które jest używane do obsługi biblioteki cyfrowej. Więcej informacji znajduje się w dokumentacji oprogramowania.
Jednym z najważniejszych czynników wpływających na rankingi wyszukiwarek internetowych jest liczba przekierowań do witryny. Generalnie, im więcej linków prowadzi do danej strony internetowej, tym lepszą pozycję zajmuje ona w rankingu wyszukiwarki. Co można zrobić, aby zwiększyć liczbę linków prowadzących do naszej witryny? Po pierwsze należy korzystać z katalogów internetowych. Są to darmowe narzędzia, które pozwalają dodać adres naszej strony do katalogów internetowych.
Kolejnym sposobem zwiększenia popularności strony jest wymiana linków pomiędzy stronami internetowymi. Najbardziej istotne są linki ze stron, które cieszą się dużą popularnością w mają podobny zakres tematyczny. Można zacząć wymianę linków stron internetowych między instytucjami, które uczestniczą w projekcie biblioteki cyfrowej. Warto zamieścić linki do strony internetowej naszej biblioteki cyfrowej na stronie lokalnej biblioteki, muzeum, czy archiwum.
Co dalej? Upewnijmy się, że strona internetowa posiada mapę. Mapa strony to lista stron wchodzących w skład witryny, dostępna dla robotów internetowych lub użytkowników. Może być to strona internetowa, które szereguje wchodzące w skład witryny strony hierarchicznie.
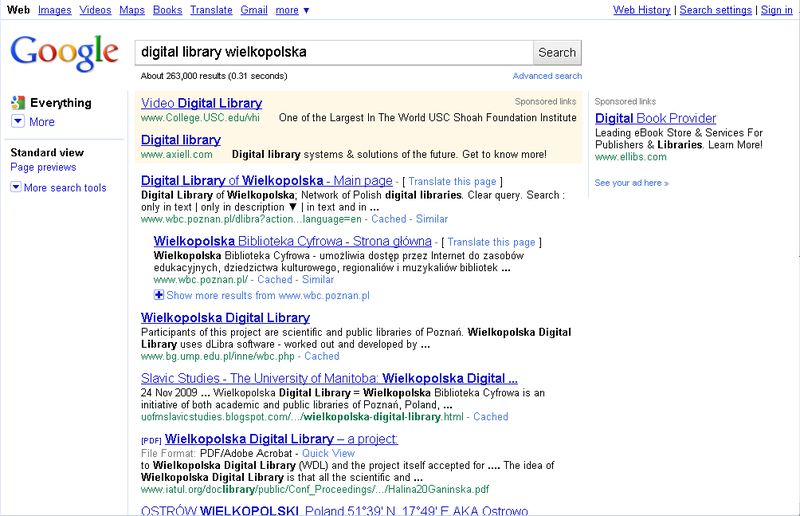
Ilustracja 40. Rezultaty wyszukiwania dla hasła 'digital library wielkopolska' [źródło].
 Ilustracja 41.
Ilustracja 41. Mapa strony Google [
źródło]
Promocja biblioteki cyfrowej - społeczność
Kolejnym ważnym aspektem promowania biblioteki cyfrowej jest stworzenie skupionej wokół niej społeczności ludzi. Większość społeczności online jest opartych na:
- grupach dyskusyjnych (Usenet)
- listach mailingowych
- forach internetowych
- kanałach IRC
- czatach internetowych
- portalach internetowych
- blogach
Której z tych technologii możemy użyć w bibliotece cyfrowej? Dobrym pomysłem jest utworzenie forum internetowego. Nie musi ono bezpośrednio odnosić się do biblioteki cyfrowej. Może być adresowane do miłośników danego regionu lub starych druków. Forum może wygenerować tysiące wiadomości dziennie i stanowić jeden z głównych powodów do odwiedzin strony.
Kolejnym sposobem kreacji społeczności jest pisanie zewnętrznego bloga korporacyjnego. Jest to publicznie dostępny blog, gdzie pracownicy biblioteki cyfrowej dzielą się swoimi spostrzeżeniami. W odróżnieniu od spontanicznych w swojej naturze blogów, blogi korporacyjne są dobrze przemyślane, stanowiąc cenne narzędzie marketingowe. Ten typ bloga może posiadać bardzo dużą liczbę odbiorców. Pisząc bloga korporacyjnego możemy nie tylko rozpowszechniać informacje, ale również wpływać na zachowania i poglądy klientów. Tym sposobem możliwe jest wspieranie marki, podtrzymywanie dobrych relacji z czytelnikami i wpływanie na wzrost zainteresowania stroną internetową. Akcje te powinny być konsekwentne i dbać o zgromadzoną społeczność. Najbardziej popularne blogi korporacyjne są pisane przez
Google (http://googleblog.blogspot.com/), Twitter (http://blog.twitter.com/), Facebook (http://blog.facebook.com/). Blog Biblioteki Cyfrowej w Teksasie (
http://www.tdl.org/blog/) to przykład bloga związanego z biblioteką cyfrową.
Kolejnym wymogiem stawianym stronie internetowej, jest posiadanie codziennie aktualizowanych elementów. Jeżeli użytkownik naszej strony zawsze znajdzie na niej nowe wiadomości, będzie ją odwiedzać niemal codziennie. Zwykle jest to motto, krótki żart. W przypadku biblioteki cyfrowej może być to cytat. Dobrym pomysłem jest prezentowanie listy ostatnio dodanych pozycji i listy pozycji rekomendowanych. Te elementy będą opisane w kolejnym rozdziale.
Facebook
Portalem społecznościowym dającym największą szansę na reklamę jest obecnie Facebook. Stał się na tyle nośnym medium, że koniecznie należy zwrócić uwagę na możliwości, które daje w zakresie promocji (i to nie tylko w aspekcie digitalizacji). To najlepszy sposób na dotarcie do najmłodszych pokoleń, potencjalnie zupełnie niezainteresowanych tematyką przedstawianą w bibliotece. Okazuje się, że wystarczy odpowiednie podejście i kompaktowa, atrakcyjna prezentacja treści, a jej zasięg może się znacznie powiększyć.
Oczywiście warto podać świetne przykłady takiej aktywności różnych bibliotek cyfrowych.
1. Na wyróżnienie zasługuje Małopolska Biblioteka Cyfrowa i jej fanpage. Można znaleźć na nim post o podobnym schemacie - zazwyczaj jest to zabawna ciekawostka lub anegdota zilustrowana wycinkiem z publikacji cyfrowej znajdującej się w tej właśnie bibliotece.
 Ilustracja 42
Ilustracja 42. Post Małopolskiej Biblioteki Cyfrowej na facebooku.
2. Świetnym przykładem jest również wspomniana już
kolekcja Cyfrowej Biblioteki Narodowej POLONA o nazwie
Fantastyka z lamusa, która powstała na podstawie
fanpage’u o tej nazwie, który z kolei założony został jako kontynuacja cyklu artykułów Agnieszki Haskiej i Jerzego Stachowicza ukazujących się na łamach “Nowej Fantastyki” od 2005 roku. Ci sami autorzy wybrali obiekty, które znajdują się w kolekcji POLONY, przez co wszystkie trzy elementy o jednej nazwie zostały ze sobą połączone, co jest przykładem umiejętnego połączenia różnych mediów i zainteresowania większej ilości użytkowaników. Zgodnie z opisem strony, artykuły i posty prezentują “wszelkie fantastyczne aspekty rzeczywistości realnej i wyobrażonej przed 1939r.”
 Ilustracja 43
Ilustracja 43. Fanpage “Fantastyka z lamusa” w portalu facebook.
3. Na uwagę zasługuje również
fanpageBiblioteki Cyfrowej Polskiego Instytutu Antropologii. Jest to po prostu dobrze i regularnie prowadzona strona, przemyślana pod względem estetycznym i graficznym (zdjęcie w tle, zdjęcie profilowe), zachęcająca do przeglądania zbiorów biblioteki cyfrowej. Prawie każdy post prezentuje archiwalne zdjęcia lub obrazy związane z tematyką portalu.
 Ilustracja 44
Ilustracja 44. Fanpage Biblioteki Cyfrowej Polskiego Instytutu Antropologicznego.
Pinterest i Tumblr
Są to portale-galerie cieszące się ogromną popularnością. Oba działają na podobnych zasadach - po założeniu konta można stworzyć galerię interesujących, inspirujących obrazów oraz ilustracji. Pinterest jest rodzajem ‘wirtualnej tablicy korkowej’, do której można “przypinać” obiekty i komponować własne kolekcje tematyczne, którym przypisane zostaną konkretne rodzaje ilustracji, co wydaje się być idealnym rozwiązaniem dla wizualnej promocji zawartości biblioteki cyfrowej.
Ilustracja 45. Profil Europeany na portalu Pinterest.
Tumblr nie ogranicza formy zamieszczanych treści do ilustracji z krótką notką, ale daje możliwość wklejania lub re-postowania tekstów, zdjęć, filmów i dźwięków w dowolnie wybranej kompozycji estetycznej. Wystarczy znaleźć odpowiadający nam graficznie “Theme”, których ilość jest obecnie niezliczona i każdy znajdzie coś dla siebie. To oczywiście, tak jak Pinterest, portal społecznościowy. Możemy wysyłać wiadomości do innych użytkowaników, obserwować wybrane ‘blogi’ (co oznacza po prostu subskrypcję ich postów do newsfeeda) by zawsze być na bieżąco z nowościami. Tumblr to wygodny portal do obserwowania interesujących ciekawostek i mimo, iż obecnie jeszcze niewiele bibliotek cyfrowych go używa, z pewnością warto wziąć pod uwagę takie rozwiązanie w aspekcie promocyjnym.
 Ilustracja 46
Ilustracja 46.
Profil Biblioteki Cyfrowej Stowarzyszenia Historycznego w Pensylwanii na portalu tumblr.
Dostarczanie obiektów cyfrowych użytkownikom
Poza promocją marki biblioteki cyfrowej należy też zadbać o odpowiednią promocję obiektów cyfrowych. Istnieje wiele działań służących promocji obiektów. W zależności od miejsca promocji możemy wyróżnić promocję na stronie internetowej biblioteki cyfrowej i poza nią. Jest też różnica między dostarczaniem zasobów użytkownikom a umożliwieniem ich przeszukiwania. W tym rozdziale opisane są metody informowania użytkowników o zasobach.
Z jednej strony, istotna jest właściwa prezentacja zasobów biblioteki cyfrowej użytkownikowi odwiedzającemu stronę internetową biblioteki. Z drugiej zaś, istotne jest zainteresowanie użytkownika, który nie odwiedza strony naszej internetowej biblioteki cyfrowej lub nie korzysta z niej regularnie.
Promocja obiektów dostępnych w bibliotece cyfrowej opiera się na zasadach opisanych w poprzednim rozdziale. Listy ostatnio dodanych pozycji to bardzo dobry przykład zmieniających się codziennie elementów, przy założeniu, że nowe obiekty pojawiają się w bibliotece cyfrowej dostatecznie często. Inną formą aktualizacji strony może być lista rekomendowanych pozycji. Personel biblioteki wybiera obiekty warte polecenia, dzięki czemu użytkownik zyskuje dostęp do interesujących zasobów bez potrzeby ich poszukiwania.
Społeczność użytkowników biblioteki cyfrowej i ruch na stronie, generowany w trakcie przeglądania zasobów, może być wykorzystany do stworzenia najczęściej oglądanych i najwyżej ocenianych obiektów. Lista najczęściej oglądanych obiektów może posiadać wiele wersji w zależności od okresu czasu, np. ostatnie 24 godziny, ostatni tydzień lub miesiąc. Oczywiście, popularność obiektu nie wpływa na jego jakość. Można dać użytkownikom instrumenty do oceniania obiektów dostępnych w bibliotece cyfrowej. To dobra i często stosowana praktyka promocji obiektów.
 Ilustracja 47.
Ilustracja 47. Lista ostatnio dodanych i najczęściej przeglądanych obiektów w bibliotece cyfrowej [
źródło].
Metodę tę można zastosować w odniesieniu do użytkowników, którzy regularnie odwiedzają stronę internetową biblioteki cyfrowej. Istnieją jednakże użytkownicy, którzy są zainteresowani zasobami biblioteki cyfrowej, ale nie odwiedzają jej regularnie. W takim przypadku można wprowadzić metodę powiadamiania użytkownika o nowościach. Najczęściej stosowane są kanały internetowe (np. kanały RSS) oraz newslettery e-mail.
Newsletter e-mailowy to znaczące narzędzie marketingowe z wieloma użytecznymi funkcjami. Informuje on użytkowników o obiektach cyfrowych w bibliotece cyfrowej i przypomina użytkownikom o istnieniu biblioteki. Zasady tworzenia newslettera poświęconego obiektom cyfrowym mogą różnić się od tych obowiązujących przy tworzeniu ogólnych newsletterów. Dobrym rozwiązaniem w tym zakresie jest danie użytkownikowi możliwości wyboru częstotliwości i treści powiadomień.
Kanały internetowe są używane w celu systematycznego powiadamiania użytkowników o zmianach zawartości serwisu. Dostawcy treści wprowadzają dla użytkowników opcję zapisywanie się do kanałów internetowych. Utworzenie kolekcji kanałów internetowych w jednym miejscu znane jest jako agregacja. Najczęściej z poziomu kanałów internetowych dostarczane są pliki HTML (zawartość stron internetowych) lub linki do stron internetowych, bądź innego typu media cyfrowe. Kanały internetowe informujące użytkowników o aktualizacjach zawartości, zawierają raczej streszczenia niż pełną zawartość treści na stronie. Dwa główne formaty kanałów intrernetowych to RSS i Atom.
Kanały internetowe mają pewną przewagę nad wysyłanymi systematycznie pocztą internetową wiadomościami:
- Użytkownicy nie muszą ujawniać swoich adresów e-mailowych podczas zapisywania się do serwisu z poziomu przeglądarki
- Użytkownicy nie muszą wysyłać prośby o wypisanie, aby nie otrzymywać więcej wiadomości. Muszą jedynie usunąć nasze źródło powiadomień ze swojego agregatora.
- Kanały internetowe są automatycznie sortowane, każdy adres URL ma swój zestaw właściwości.
Do używania kanałów internetowych wymagany jest czytnik. Narzędzie to funkcjonuje jak automatyczny program do obsługi poczty internetowej, nie jest jednak wymagany adres e-mail. Użytkownik zapisuje się do konkretnego kanału internetowego i otrzymuje aktualizowaną treść, zawsze ilekroć jest ona aktualizowana.
Kanały internetowe mogą być używane w bibliotece internetowej do informowania o nowo dodanych obiektach internetowych. Mogą one być używane do dostarczania informacji dotyczących całych kolekcji lub pojedynczych przedmiotów. Kanały internetowe są generowane automatycznie przez oprogramowanie do obsługi bibliotek cyfrowych.
Usługa informowania użytkowników o zasobach jest kierowana do tych internautów, którzy co najmniej raz odwiedzili stronę internetową biblioteki cyfrowej. Jednak większość użytkowników Internetu nigdy nie odwiedziła strony biblioteki. Im właśnie powinno się umożliwić dotarcie do obiektów cyfrowych poza stroną internetową biblioteki.
Częstym sposobem promowania obiektów cyfrowych w Internecie jest umieszczanie linków do tych zasobów na stronach internetowych. Można posłużyć się stronami internetowymi instytucji, które współtworzą bibliotekę internetową, np. lokalnymi bibliotekami lub muzeami.
Wymiana linków do zasobów cyfrowych pomiędzy znajomymi to bardzo mocna i efektywna metoda promocji. Może ona być wspierana opcją rekomendacji, np. poprzez e-mail. Dzięki temu możliwe będzie poinformowanie znajomych o interesującym zasobie w bibliotece cyfrowe przez wybranie odpowiedniej opcji na stronie internetowej.
Interesującym pomysłem jest umożliwienie użytkownikom oglądania obiektów cyfrowych na stronach internetowych nie wchodzących w skład witryny biblioteki cyfrowej. Wprowadzanie filmów wideo na YouTube jest jedną z kluczowych funkcji tego serwisu internetowego. Użytkownicy nie muszą odwiedzać danej witryny, żeby obejrzeć film. W gruncie rzeczy nie muszą być nawet świadomi istnienia serwisu, z którego korzystają. Na podobnej zasadzie może działać promocja zasobów biblioteki cyfrowej.
 Ilustracja 48.
Ilustracja 48. Film wideo pochodzący z serwisu YouTube, osadzony na innej stronie.
Wyszukiwanie obiektów cyfrowych
Odpowiednia promocja biblioteki cyfrowej przyczynia się do stworzenia dobrego wizerunku, zwiększa obecność biblioteki w Internecie, przyciąga nowych użytkowników oraz powoduje, że dotychczasowe grupy użytkowników nadal są zainteresowane korzystaniem z biblioteki. Obiekty cyfrowe mogące być interesujące dla użytkowników są dostarczane im za pomocą różnych kanałów i metod, podobnie jak w przypadku tradycyjnej biblioteki, w której użytkownicy mają oferowaną możliwość wyszukania interesujących ich zasobów. Można wyróżnić kilka profili użytkowników. W pierwszym przypadku, użytkownik wie dokładnie czego szuka, na przykład zna tytuł i nazwisko autora książki. Użytkownik taki może również chcieć znaleźć wszystkie książki danego autora lub wszystkie numery czasopisma w danym roku. W drugim przypadku użytkownik nie potrafi dokładnie określić obiektu, na przykład zna tylko nazwisko autora książki, ale nie pamięta tytułu. W ostatnim przypadku użytkownik nie szuka żadnego konkretnego zasobu, ale poszukuje obiektów mogących być w polu jego zainteresowania, na przykład przeglądając zasoby dotyczące historii regionu, z którego pochodzi. Jak pomóc wszystkim z tych użytkowników odnaleźć interesujące ich zasoby? Niezbędne jest zapewnienie odpowiedniej funkcjonalności wyszukiwania, dostępnej w miejscu pracy użytkownika. Są to głównie typowe narzędzia wyszukiwania - wyszukiwarki i formularze umieszczone na witrynie biblioteki cyfrowej. Oprócz tego istnieją rozwiązania opracowane specjalnie na potrzeby wyszukiwania zasobów w bibliotekach cyfrowych.
Promocja biblioteki cyfrowej i dostarczanie użytkownikom informacji na temat zasobów wymaga dużego nakładu pracy i wielu różnych działań. W przypadku narzędzi wyszukiwawczych sytuacja jest nieco inna, ponieważ większość pracy jest wykonywana automatycznie.
W jaki sposób typowy użytkownik Internetu wyszukuje informacji w sieci? Używa on zwykle wyszukiwarki Google, generalnie biorąc wyszukiwarki internetowej. Co trzeba zatem zrobić, żeby zasoby biblioteki cyfrowej były widoczne w wyszukiwarce? Tak naprawdę nic. Najczęściej stosowane systemy tworzenia bibliotek cyfrowych są zaprojektowane w ten sposób, żeby maksymalnie zwiększyć widzialność zasobów w Internecie. Jeśli używa się jednego z popularnych programów i nasza biblioteka jest publicznie dostępna, można być spokojnym, że użytkownicy łatwo znajdą te zasoby.
Użytkownicy biblioteki cyfrowej powinni mieć możliwość wyszukiwania z menu witryny biblioteki. System tworzenia bibliotek cyfrowych zapewnia standardowe rozwiązania takie, jak:
- formularz wyszukiwania prostego
- formularz wyszukiwania zaawansowanego
- indeksy wyszukiwania.
 Ilustracja 49.
Ilustracja 49. Formularze wyszukiwania prostego i zaawansowanego. [
źródlo]
Przede wszystkim formularz wyszukiwania prostego musi być umieszczony w miejscu, w którym większość użytkowników się go spodziewa. Musi on umożliwiać szybkie wyszukiwania przez wpisanie zapytania i wysłanie go bez zmiany innych parametrów w formularzu. Obok formularza wyszukiwania prostego powinien znajdować się odnośnik do formularza wyszukiwania zaawansowanego. Innym systemem, umożliwiającym wyszukiwanie obiektów są indeksy wyszukiwania, na przykład tytułów, autorów lub słów kluczowych. Indeks jest listą wartości danych atrybutów (np. tytułów) w układzie alfabetycznym. Przypomina on karty katalogowe w tradycyjnych bibliotekach. Formularze wyszukiwania i indeksy działają w pełni automatycznie. Po dodaniu nowego obiektu do biblioteki cyfrowej indeksy są automatycznie aktualizowane i nowe obiekty można wyszukać za pomocą formularzy wyszukiwania.
Interesującym dodatkiem na wielu stronach jest wtyczka do wyszukiwania. Umożliwia ona dostęp do wyszukiwarki z poziomu przeglądarki internetowej, bez potrzeby odwiedzania witryny, na której wyszukiwarka działa. Wtyczki takie są dostępne w systemach do tworzenia bibliotek cyfrowych.
 Ilustracja 50.
Ilustracja 50. Wtyczka do wyszukiwania z biblioteki cyfrowej opartej na systemie DSpace. [
źródło]
Czym jest cyfrowa kopia główna i jakie jest jej znaczenie?
Wstęp
Pojęcie cyfrowej kopii głównej - egzemplarza wzorcowego zostało już wprowadzone w poprzednich częściach kompendium. Ta część ma na celu podsumowanie i poszerzenie wcześniejszych wiadomości. W kolejnych częściach będzie mowa o długoterminowej konserwacji materiałów cyfrowych (ang. long term preservation). Termin ten jest stosowany do opisania całego zbioru kwestii związanych z zapewnieniem dostępności treści intelektualnych zawartych w obiektach cyfrowych w długiej perspektywie czasowej.
Dobrze udokumentowana i wysokiej jakości główna kopia cyfrowa - egzemplarz wzorcowy jest bardzo ważna w kontekście długoterminowej konserwacji, z ich przechowywaniem wiąże się jednak kilka problemów. W niniejszej części opisane zostaną pewne możliwe rozwiązania dla tychże problemów.
Cyfrowa kopia główna
Po zapoznaniu się z kompendium powinno stać się jasne, dlaczego należy skanować w najlepszej możliwej jakości oraz jakie są zalety i wady takiego podejścia. Jak wiadomo, cyfrowa kopia główna jest oryginalnym plikiem stworzonym w trakcie procesu skanowania. Jako że skanowanie należy wykonywać tak rzadko, jak to tylko możliwe, cyfrowa kopia główna powinna zawierać największą możliwą ilość szczegółów. Oczywiste jest również, że poziom szczegółowości lub ilość informacji cyfrowej jest bezpośrednio związany z ostatecznym rozmiarem pliku.
Co to oznacza w rzeczywistości? Rozmiar pliku zależy od parametrów skanowania:
- obraz o rozdzielczości 300 dpi, zapisany w formacie TIFF (z kompresją bezstratną) może mieć wielkość ponad 40 MB.
- jedna godzina nieskompresowanego filmu w rozdzielczości 720x576 pikseli z 25 klatkami na sekundę (standardowa jakość w telewizji - system PAL) będzie zajmować 93 GB.
W przypadku kolekcji 1000 zdjęć będzie to oznaczało 40 GB danych. Ponieważ pamięci (tzn. twarde dyski) stają się coraz tańsze, te ilości danych nie powinny przerażać. Jeśli weźmie się jednak pod uwagę skanowane książki, która może mieć setki stron, liczby te mogą znacznie wzrosnąć.
Pojawia się również pytanie - co z materiałami natywnie cyfrowymi (ang. born digital)? Pojęcie cyfrowej kopii głównej - egzemplarza wzorcowego ma zastosowanie również w przypadku takich obiektów. Również w ich przypadku może okazać się konieczne stworzenie wersji prezentacyjnej i w związku z tym należy pamiętać o zabezpieczeniu oryginału.
Zaprezentowany powyżej przykład pokazuje, że materiały multimedialne zajmują większe ilości miejsca niż tradycyjne obrazy czy pliki tekstowe. Oczywiście rozmiar pliku może być zmniejszony przez zastosowanie którejś z metod kompresji bezstratnej (w przypadku egzemplarzy wzorcowych tylko takie metody powinny być rozważane), ale podobnie jak w przypadku wyboru formatu plików, metoda kompresji powinna być szeroko akceptowanym standardem.
Zanim użytkownik kompendium zapozna się z sugerowanymi rozwiązaniami dotyczącymi wyboru formatu plików i rozwiązywania problemów z przechowywaniem, kolejna część będzie dotyczyć pojęcia długoterminowej konserwacji.
Długoterminowe przechowywanie materiałów cyfrowych
W różnych miejscach tego kompendium jako jeden z najważniejszych celów digitalizacji było wymieniane długoterminowe przechowywanie/konserwacja materiałów cyfrowych. Łączą się w nim różne pojęcia związane z digitalizacją i bibliotekami cyfrowymi. Podobnie jak obiekty analogowe, zawartość cyfrowa jest podatna na różne zagrożenia, w tym:
- Wychodzenie formatu z użytku,
- Wiąże się to z brakiem oprogramowania zdolnego do poprawnego wyświetlenia zawartości danego pliku dane są więc uwięzione w nierozwijanym już formacie.
- Fizyczne starzenie/uszkodzenie się nośnika,
- Przypadkowe zarysowanie powierzchni dysku DVD, na którym przechowywana jest kopia obiektu cyfrowego może mieć fatalny wpływ na możliwość odczytania zawartości obiektu.
- Wychodzenie z użytku nośnika
- Dokładnie tak samo, jak w przypadku wychodzenia z użytku formatu plików, również nośnik może stać się niemożliwy do odczytania z powodu braku odpowiedniego sprzętu - wystarczy przypomnieć sobie dyskietki 3,5 cala. Dostępność sprzętu, za pomocą którego można odczytać ich zawartość jest obecnie mocno ograniczona.
- Brak informacji pozwalającej na poprawną interpretację intelektualnych treści obiektu,
- Z czasem wiedza na temat interpretacji informacji zawartej w danym obiekcie może zaniknąć. Wystarczy wyobrazić sobie zdjęcie ukazujące budynek, który już nie istnieje. Z biegiem czasu wiedza na temat jego istnienia (położenia) może ulec zatarciu i identyfikacja zawartości danego zdjęcia będzie niemożliwa.
- Trwałość instytucjonalna
- Jeśli zostanie zlikwidowana instytucja lub upadnie firma, która zapewnia działanie danemu repozytorium, co stanie się z ich aktywami cyfrowymi?
Jak widać obiekty cyfrowe mogą być w rzeczywistości bardzo nietrwałe.
Autorzy poradnika "Some Preliminary Ideas Towards a Theory of Digital Preservation" [
źródło] stwierdzają, że "Zagadnienie przechowywania materiałów cyfrowych jest obecnie jednym z najtrudniejszych problemów badawczych dla środowiska bibliotek cyfrowych, skupiającym na sobie uwagę zarówno badaczy, jak i praktyków". Długoterminowe przechowywanie nie jest prostą kwestią, w trakcie całego przebiegu digitalizacji zawsze powinno się pamiętać o wspomnianych zagrożeniach. W poprzednich rozdziałach często podkreślany był fakt, że oparcie się na standardach jest najważniejsze do zapewnienia długoterminowego dostępu do zasobów. W kolejnych omówiona zostanie rola metadanych w zapewnieniu dostępu do intelektualnych treści obiektu. Cyfrowe kopie główne, dzięki wysokiej jakości powinny gwarantować, że cyfrowe wersje obiektów będą w pełni przedstawiać obiekt oryginalny nawet jeśli oryginał przestanie być dostępny.
Pełny przegląd zagadnień związanych z długoterminowym przechowywaniem nie mieści się w zakresie niniejszego kompendium. Wspaniałym zasobem omawiającym ten temat jest kurs
Digital Preservation Management Tutorial.
Przechowywanie cyfrowych kopii głównych
Po zakończeniu procesu skanowania należy się upewnić, że rezultaty pracy będą bezpiecznie przechowane w odpowiednio do tego celu przygotowanym miejscu. We wcześniejszych częściach tego kompendium zawarto wiele przykładów pokazujących, jak duża może być cyfrowa kopia główna. Aby zarchiwizować tak wielką ilość danych należy zdecydować, który nośnik będzie najbardziej wydajny w danym przypadku. Nie jest to proste, jednak w dalszej części będzie można dowiedzieć się więcej na ten temat.
Aby mieć przynajmniej pewien stopień pewności, że archiwum cyfrowych kopii głównych - egzemplarzy wzorcowych nie ulegnie zniszczeniu lub uszkodzeniu w trakcie jakiegoś wypadku losowego, należy również pomyśleć o kopii zapasowej. Jeśli kolekcja będzie ciągle się rozrastać jej twórcy z pewnością staną przed problemem związanym z niewystarczającą ilością miejsca. Jak rozwiązać ten problem?
Przechowywanie na nośniku fizycznym
Istnieje wiele rodzajów nośników, które mogą być użyte do przechowywania dużych ilości danych. Według już cytowanego kursu edukacyjnego
"Digital Preservation Management" wśród najlepszych możliwych rozwiązań zostały wymienione płyty CD-R/DVD-R i taśmy magnetyczne DLT (ang. Digital Linear Tapes). Wybór ten został oparty na podstawie porównania tych nośników pod względem trwałości, pojemności, żywotności, starzenia się technologii i kosztów. Porównanie to nie uwzględnia dysków SSD i zwykłych dysków twardych, które są całkiem wygodnym i stosunkowo tanim sposób przechowywania zawartości cyfrowej, ale wymagają ostrożności przy użytkowaniu.
Przechowywanie danych na nośnikach fizycznych wymaga ciągłej uwagi. Niektóre badania przeprowadzone w National Institute of Standards and Technology (NIST) [
źródło] sugerują, że płyty DVD-R powinny być czytelne przez 30 lat (zakładając, że są przechowywane w temperaturze 25°C przy wilgotności względnej 50%).
Jak widać przy przechowywaniu danych na dyskach optycznych, takich jak CD lub DVD, należy zdawać sobie sprawę, że za jakiś czas będą one wymagały odświeżenia. Oprócz tego należy również pamiętać o odpowiednim postępowaniu i przechowywaniu (np. nie układać dysków CD jeden na drugim) w bezpiecznym, suchym miejscu. Aby w razie potrzeby odnalezienie danego zasobu było możliwe, każdy dysk musi być odpowiednio opisany.
Wspomniano, że bardzo wydajnym sposobem przechowywania danych są również taśmy magnetyczne DLT. Są one używane głównie w dużych centrach przechowywania danych. Oprócz zakupienia samego nośnika, należy jeszcze posiadać odpowiednie urządzenie umożliwiające zapisywanie i odczytywanie danych na taśmie. Nagrywarki i napędy CD/DVD są bardzo powszechnie i zwykle nie ma potrzeby kupować ich specjalnie na potrzeby wykonywania cyfrowych kopii głównych. Trudno jest sobie wyobrazić, że czytnik taśm magnetycznych będzie przydatny w małej instytucji kultury o ograniczonych zasobach i niewielu zatrudnionych informatykach, lub w ogóle ich pozbawionej.
Innym rozwiązaniem jest przechowywanie danych na twardym dysku, przy czym alternatywą dla tradycyjnych twardych dysków są dyski SSD, które są wciąż bardzo kosztowne. Twarde dyski są bardziej pojemne niż dyski optyczne i zapewniają wygodniejszy dostęp do danych. Zewnętrzny dysk twardy, który może być łatwo podłączony do komputera za pomocą złącza USB są niekosztowne i dość szybkie. Oprócz dysków zewnętrznych USB należy również wziąć pod uwagę tradycyjne twarde dyski 3,5 cala, które są tańsze i mogą być podłączone bezpośrednio do kontrolera twardego dysku komputera.
Bez względu na wybór nośnika należy pamiętać o następujących kwestiach:
- wybór znanych marek gwarantuje przyzwoity poziom jakości,
- nośniki powinny być przechowywane w odpowiednich warunkach i zgodnie z zaleceniami producenta.
Przechowywanie danych w firmie zewnętrznej
Można zdecydować się na przechowywanie danych na nośnikach fizycznych, stworzyć magazyn nośników w danej instytucji i przechowywać w nim wszystkie dyski optyczne lub dyski twarde. W poprzedniej części wspomniano, że czasem jedna kopia nie wystarcza. Jeśli zapadnie decyzja o stworzeniu dodatkowej kopii zasobów, lub po prostu nie chcąc borykać się z przechowywaniem setek lub tysięcy dysków optycznych, można zdecydować się na przechowywanie zasobów w zdalnym lub zewnętrznym centrum danych lub poprosić o pomoc większą instytucję.
Sprzęt do przechowywania staje się coraz bardziej dostępny, podobnie jak usługi przechowywania danych on-line. Istnieje kilka różnych typów takich serwisów: narodowe banki danych, serwisy do przechowywania danych on-line i zwykłe serwisy hostingowe. Dzięki korzystaniu z usług firm zewnętrznych można uniknąć wszystkich problemów związanych z przechowywaniem danych, takich jak odświeżanie nośnika, możliwe uszkodzenia i wypadki prowadzące do utraty danych.
Chcąc skorzystać z możliwości przechowywania danych on-line, należy pamiętać o przepustowości sieci. Niektóre z firm prowadzących takie usługi mogą otrzymywać dane na dyskach fizycznych, tak więc można wysłać im zestaw płyt DVD za pomocą tradycyjnej poczty. Narodowe banki danych (w Polsce - Krajowy Magazyn Danych, KMD) mogą zapewniać darmowe usługi hostingowe dla niektórych grup instytucji publicznych. Banki te są zwykle odpowiednio zabezpieczone przed możliwymi wypadkami i awariami technicznymi.
W sieci działają również liczne serwisy stworzone z myślą o tworzeniu kopii zapasowych. Oferują one dedykowane oprogramowanie, zapewniające synchronizację między twardym dyskiem komputera i kopią on-line. Różni dostawcy mogą zapewniać różne warunki, np. ustaloną ilość danych lub ustaloną liczbę komputerów, z których będą tworzone kopie zapasowe.
Oprócz usług takich, jak opisane powyżej, można również wykupić miejsce do przechowywania danych on-line, dostępne za pomocą standardowych protokołów takich, jak FTP lub HTTP.
W przypadku usług komercyjnych najczęściej jest możliwość przetestowania usług przed zakupem. Jest to dobra okazja do sprawdzenia, czy oferowane przez dostawcę komercyjnego usługi odpowiadają potrzebom danej instytucji.
W przypadku skorzystania z oferty dostawców zewnętrznej przestrzeni magazynowej bezpieczeństwo danych zależy tylko od możliwości opłacenia takiej usługi.
Jeśli instytucja nie ma pieniędzy, ani wykwalifikowanego personelu pozwalającego na użycie rozwiązań zaproponowanych powyżej, można spróbować nawiązać współpracę z jakąś większą instytucją, np. regionalną biblioteką, dużą biblioteką uniwersytecką lub centrum komputerowym.
Sumy kontrolne
Suma kontrolna jest bardzo przydatną rzeczą. Jeśli ktoś o niej słyszał, prawdopodobnie wie, że ta idea pochodzi z kryptografii. Suma kontrolna jest rodzajem unikatowego identyfikatora jednego lub więcej plików i jest tworzona na podstawie analizy zawartości pliku. Algorytmy tworzenia sum kontrolnych gwarantują, że jeśli zawartość pliku ulegnie zmianie, identyfikator również się zmieni. Dlaczego jest to takie przydatne?
Fizyczne nośniki mogą zostać uszkodzone, a w rezultacie część danych może ulec zniszczeniu, a część uszkodzeniu lub zmianie. Jeśli przechowuje się sumę kontrolną oprócz cyfrowej kopii głównej - egzemplarza wzorcowego, zyska się kolejny sposób weryfikacji tego, czy plik jest wciąż czytelny i nieuszkodzony. Oczywiście sumy kontrolne również mogą ulec uszkodzeniu, ale ponieważ pliki je zawierające są bardzo małe (szczególnie w porównaniu z kopią wzorcową), przechowywanie ich kopii nie powinno być problemem.
Najbardziej popularnymi algorytmami generowania sum kontrolnych są MD5 i SHA1. Popularne programy, takie jak
Total Commander zapewniają wbudowaną funkcję tworzenia sum kontrolnych dla dowolnego pliku. Wystarczy zaznaczyć jeden lub więcej plików, dla których chce się stworzyć sumy kontrolne, przejść do menu
File i wybrać polecenie "
Create CRC checksum". W następnym kroku pojawi się okno dialogowe, w którym można wybrać nazwę pliku z sumą kontrolną (domyślnie jest to nazwa oryginalnego pliku oraz nazwa algorytmu) i kliknąć OK. Następnie program stworzy sumy kontrolne dla danego pliku lub plików.
W celu weryfikacji, czy suma kontrolna pliku jest zgodna z zawartością należy:
- Uruchomić program Total Commander,
- Skopiować sumę kontrolną pliku do tego samego folderu, w którym znajduje się egzemplarz wzorcowy,
- Wybrać kursorem plik z sumą kontrolną,
- Przejść do menu, wybrać polecenie File, a następnie "Verify CRC checksum"
- Wynik weryfikacji zostanie wyświetlony przez program.
Powinno się poważnie rozważyć użycie tego prostego środka zabezpieczającego. Przy istnieniu sum kontrolnych stosunkowo łatwo zautomatyzować proces weryfikacji spójności nośnika.
Wybór formatu do archiwizacji
Wybór formatu plików do archiwizacji nie jest prostym zadaniem, jest jednak kilka artykułów poświęconych porównaniu różnych formatów. W tej części można będzie się zapoznać z głównymi cechami, którymi powinny się charakteryzować formaty do archiwizacji.
- Otwarte, powszechnie używane standardy
- Otwarty standard oznacza, że jego specyfikacja (szczegółowy opis techniczny, pozwalający na interpretację zawartości) jest dostępna publicznie. Jest to ważne, ponieważ producenci oprogramowania mogą zrezygnować z danego formatu. Dzięki otwartej specyfikacji będzie w takim przypadku możliwe opracowanie narzędzi do obsługi danego formatu niezależnie od pierwotnego dostawcy.
- Solidność
- Dobry format plików powinien łączyć duże możliwości i prostotę struktury.
- Elastyczność
- Niektóre formaty działają jak opakowanie, umożliwiające stosowanie różnych algorytmów kompresji. Niektóre z nich, jak np. JPEG2000, umożliwia stosowanie kompresji zarówno stratnej, jak i bezstratnej, inne, takie jak TIFF mogą być używane z kompresją bezstratną albo bez kompresji.
- Niezależność od platformy
- Dobry format powinien być przenośny, tak aby umożliwić jego odtwarzanie na dowolnej platformie, tzn. zarówno na Linuksie, jak i na Windows.
- Możliwość osadzenia metadanych
- Możliwość osadzenia metadanych wewnątrz formatu do archiwizacji wydaje się być bardzo dobrym rozwiązaniem. W związku z tym, że rekord metadanych, opisujących dany plik (lub obiekt, którego plik jest częścią) może się zmieniać w czasie, dobrze jest osadzić niektóre najbardziej podstawowe metadane w cyfrowej kopii głównej - egzemplarzu wzorcowym.
- Dostępność mechanizmów konwersji
- Wbudowane mechanizmy umożliwiające wykrywanie błędów i naprawę uszkodzonego pliku.
- Niektóre formaty mogą zawierać możliwość powtarzalności niektórych danych lub inne mechanizmy naprawy.
Nie trzeba samemu dokonywać oceny wszystkich istniejących formatów plików. W kolejnych częściach będzie można się dowiedzieć, które formaty plików powinny być używane do danego typu zawartości. Istnieją również różne formalne metodologie, czasem wdrażane jako programy komputerowe, możliwe do użycia w przypadku konieczności szczegółowych badań.
Sugerowane formaty do archiwizacji i ich parametry
W poprzedniej lekcji, w ramach tego tematu zaprezentowano sugestie rozwiązań, dotyczących formatów plików dla różnego rodzaju mediów. Kolejne trzy części zawierają podsumowanie tego, co zostało już powiedziane oraz dodatkowe, użyteczne informacje, dotyczące różnych typów treści, z którymi można się spotkać.
Sugerowane formaty do archiwizacji i ich parametry: obrazy nieruchome
Poniższe sugestie pochodzą z dokumentu technicznego Biblioteki Kongresu [
źródło], zatytułowanego "Technical Standards for Digital Conversion of Text and Graphic Materials".
- Tekst drukowany: książki ilustrowane, druki ulotne, karty zapisane pismem maszynowym, czasopisma
- w przypadku tekstu w formie graficznej:
- co najmniej 300 PPI,
- 8-bitowa skala szarości
- dla potrzeb OCR:
- 400 PPI,
- 8-bitowa skala szarości
- Muzykalia: zapisy nutowe, partytury z adnotacjami, manuskrypty muzyczne:
- Dostęp do zawartości:
- co najmniej 300 PPI,
- 8-bitowa skala szarości lub kolor 24-bitowy w przypadku, gdy kolor jest ważną cechą dokumentu
- Rozpoznanie artefaktów:
- 400 PPI,
- 8-bitowa skala szarości
- Manuskrypty: pismo ręczne lub maszynowe
- Dostęp do zawartości:
- co najmniej 300 PPI,
- 8-bitowa skala szarości lub kolor 24-bitowy w przypadku, gdy kolor jest ważną cechą dokumentu
- Rozpoznanie artefaktów:
- 400 PPI,
- 8-bitowa skala szarości
- Materiały kartograficzne: drukowane w skali szarości lub kolorze do rozmiaru D (864 × 559 mm)
- Badanie zawartości:
- co najmniej 250 PPI - rozdzielczość zależy od rozmiaru mapy, w szczególności gdy poszczególne fragmenty mapy muszą być sklejane i rozmiar pliku wzrasta do 500 MB i powyżej,
- kolor 24-bitowy
- Reprodukcja map:
- Fotografie: płynne przejścia tonalne, kolor
- Dostęp do zawartości:
- co najmniej 300 PPI,
- 8-bitowa skala szarości lub kolor 24-bitowy w przypadku, gdy kolor jest ważną cechą dokumentu
- Reprodukcja:
- należy użyć najwyższej dostępnej rozdzielczości dla danego urządzenia
- co najmniej 24-bitowy kolor
- Grafika artystyczna: oryginały o ograniczonej liczbie tonów, materiały kolorowe o płynnych przejściach tonalnych
- Dostęp do zawartości:
- co najmniej 300 PPI,
- 8-bitowa skala szarości lub kolor 24-bitowy w przypadku, gdy kolor jest ważną cechą dokumentu
- Reprodukcja:
- należy użyć najwyższej dostępnej rozdzielczości dla danego urządzenia
- co najmniej 24-bitowy kolor
- Stare druki: obiekty o wysokiej wartości artystycznej
- Rozpoznanie wartości artystycznych:
- co najmniej 400 PPI,
- 24-bitowy kolor
- Prace badawcze nad wartościami artystycznymi:
- co najmniej 600 PPI,
- co najmniej 24-bitowy kolor
Powyższe zalecenia mogą być stosowane w praktyce.
Cyfrowe kopie główne obrazów nieruchomych zwykle są przechowywane jako pliki w formacie TIFF 6.0 lub JPEG2000 z kompresją bezstratną. Nazwa standardu TIFF pochodzi od Tagged Image File Format. TIFF jest to szeroko używanym formatem (pierwsza wersja specyfikacji została opublikowana w 1986), elastycznym i dającym się łatwo przystosować. W pliku TIFF obraz można przechowywać zarówno w formacie skompresowanym, jak i nieskompresowanym, do kompresji można stosować algorytmy stratne lub bezstratne.
JPEG2000 jest standardem kompresji obrazu i systemem kodowania opracowanym przez komitet Joint Photographic Experts Group w 2000 r. Charakteryzuje się on bardzo ciekawymi cechami, wśród których najbardziej warte wymienienia to:
- Możliwość stosowania zarówno kompresji stratnej, jak i bezstratnej.
- Wbudowany mechanizm naprawy błędów spowodowanych szumami w kanałach komunikacyjnych.
- Możliwość przechowywania w jednym pliku obrazu w różnych rozdzielczościach.
- Dokładnie tak samo jak TIFF ma możliwość osadzania metadanych.
Oba formaty plików wydają się być dobrym rozwiązaniem dla cyfrowych kopii głównych - egzemplarzy wzorcowych, jednak w momencie powstawania tego kursu JPEG 2000 jest wciąż dość nowym formatem w porównaniu z TIFF. Ten ostatni jest w rzeczywistości o wiele mniej skomplikowany niż JPEG 2000. Te dwa argumenty mogą przemawiać za tym, że format TIFF jest lepszym wyborem.
Sugerowane formaty do archiwizacji i ich parametry: zawartość tekstowa
Po otrzymaniu obrazu nieruchomego i przeprowadzeniu rozpoznania OCR zawartości tekstowej należy podjąć decyzję jak (i co) przechowywać jako cyfrową kopię główną - egzemplarz wzorcowy obiektu tekstowego. Ponieważ rozpoznawanie znaków tekstowych zabiera również dużo czasu i jest czynnością kosztowną, warto przechowywać nie tylko oryginalne obrazy z urządzenia skanującego, ale również rezultaty rozpoznawania OCR.
Istnieją dwa sposoby na przechowywanie obrazów razem z rozpoznanym tekstem:
- Najprostszym rozwiązaniem jest umieszczenie pliku tekstowego obok każdego obrazu, przy czym plik tekstowy powinien być zakodowany w standardzie UTF-8. Rozwiązanie to może być użyte tylko, gdy tekst widoczny na obrazie ma prosty układ i nie ma zaawansowanego formatowania.
- Programy OCR oprócz samego tekstu podają również informację o położeniu tekstu na stronie. Informacja ta powinna być zachowana, ale ten prosty plik tekstowy nie daje takiej możliwości.
- Programy OCR, takie jak ABBYY Finereader umożliwiają wyeksportowanie rezultatów OCR do OCR XML, który może być przekonwertowany na otwarte standardy takie jak TEI P5 lub TEI Lite. Można również zachować ten XML obok każdej ze strony.
- Innym rozwiązaniem jest użycie ustandaryzowanego pliku PDF/A, który może zawierać zarówno tekst, jak i oryginalne obrazy w takiej postaci, w jakiej zostały wytworzone (TIFF lub JPEG2000). Większość istniejących narzędzi do OCR umożliwia zachowanie rezultatów OCR jako plik PDF, tak więc użycie tego rozwiązania jest dość proste.
Sugerowane formaty do archiwizacji i ich parametry: materiały dźwiękowe i filmowe
Ogólnie rzecz biorąc, materiały dźwiękowe i filmowe powinno się zachowywać w takiej formie, w jakiej uległy wytworzeniu w urządzeniu nagrywającym. Cyfrowa kopia główna (egzemplarz wzorcowy) zawierający takie surowe dane może być zakodowana z użyciem zamkniętego formatu wspieranego tylko przez wytwórce sprzętu. W niektórych przypadkach konwersja do formatu otwartego może być niemożliwa, gdyż spowodowałaby utratę jakości. W takiej sytuacji oprócz cyfrowych kopii głównych, powinno się rozważyć zachowanie odpowiedniego oprogramowania.
Zarówno w przypadku materiałów dźwiękowych, jak i filmowych rekomendacje oparto na dokumencie "MINERVA Technical Guidelines for Digital Cultural Content Creation Programmes" [
źródło].
Dla plików dźwiękowych powinno się używać formatów WAV lub AIFF z co najmniej 24 bitami na kanał dzwięku (przy czym należy zachować wszystkie kanały) próbkowane z częstotliwością co najmniej 48/96 KHz. Jeśli wielkość pliku zacznie być problemem, można użyć bezstratnych algorytmów kompresji takich jak FLAC lub LPCM.
Filmy, gdy to możliwe, powinny być przechowywane w nieprzetworzonym formacie AVI, bez użycia jakichkolwiek kodeków, z oryginalną wielkością klatki, przy 25 klatkach na sekundę, z użyciem 24-bitowego koloru.
Konwencje nadawania nazw plikom
Zwykle nie przywiązuje się dużej wagi do nadawania nazw plikom, lecz jeśli zachodzi potrzeba przeniesienia plików z jednego systemu operacyjnego do innego, kwestia nazw plików staje się bardzo istotna.
We współczesnych systemach operacyjnych plikowi można nadać prawie każdą nazwę. Jednak różne systemy operacyjne używają różnych sposobów na kodowanie znaków takich jak spacje, litery spoza alfabetu łacińskiego. Tak więc użycie któregoś z tych znaków może spowodować problemy przy przesyłaniu plików w sieci [
źródło].
System plików dla dysków optycznych jest określony w standardzie ISO 9660. Ma on na celu wsparcie różnych systemów komputerowych w taki sposób, żeby była możliwa wymiana danych. Krótko mówiąc, standard ten używa konwencji krótkich nazw plików (standard 8.3). Oznacza to, że nazwa pliku składa się z co najwyżej 8-literowej nazwy, kropki i co najwyższej trzyliterowego rozszerzenia.
Zarówno nazwa, jak i rozszerzenie nie powinny zawierać żadnych znaków interpunkcyjnych, takich jak \,/,:,?,”,<>, ponieważ niektóre z nich mogą mieć w określonych systemach operacyjnych specjalne przeznaczenie. Nie powinno się również używać spacji, można ją zastąpić łącznikiem lub podkreśleniem. Zarówno w nazwie, jak i w rozszerzeniu powinno się używać tylko liter alfabetu łacińskiego.
Należy unikać sytuacji, w której nie podano rozszerzenia pliku. W rozszerzeniu jest zawarta informacja o formacie pliku, stąd jest ono ważne dla użytkowników, którzy będą chcieli obejrzeć zawartość danego pliku.
O czym należy pamiętać?
Jest to lista kontrolna rzeczy, o których należy pamiętać przed i po publikacji. W większości uwzględnia ona jednak sprawy, o których trzeba pomyśleć od samego początku np. uzyskanie zgody autora na publikacje, czy przygotowanie kopii archiwalnej.
Poniższa lista jest podzielona na dwie części. Osobno wyszczególniono rzeczy do sprawdzenia przed i po publikacji. Część zadań powtarza się na obu listach. W przypadku małych instytucji, w których za cały proces digitalizacji jest odpowiedzialna jedna osoba, nie trzeba sprawdzać niektórych rzeczy powtórnie. Jeśli zakres odpowiedzialności jest podzielony między kilka osób lub pewną liczbę oddzielnych zespołów, należy upewnić się, że sprawdzono wszystkie punkty.
Przed publikacją
Prawa własności intelektualnej
Prawa własności intelektualnej to podstawowa rzecz do sprawdzenia nie tyle przed samą publikacją, co przed wyborem obiektów do digitalizacji. Prawa dotyczące własności intelektualnej nie zabraniają bibliotekarzowi digitalizacji książki, mogą natomiast pojawić się problemy związane z publicznym udostępnieniem obiektu cyfrowego.
W przypadku obiektów, które znajdują się w domenie publicznej należy pamiętać, że ich cyfrowa kopia również jest obiektem znajdującym się w domenie publicznej.
Dla obiektów natywnie cyfrowych może pojawić się problem nadania odpowiedniej licencji. Przy wyborze należy wziąć pod uwagę charakter obiektu i oryginalny zamiar autora dzieła.
Schemat metadanych
Metadane muszą być przygotowane zgodnie z odpowiednim schematem i zasadami użycia. Należy upewnić się, że biblioteka cyfrowa zapewnia obsługę schematu, w którym przygotowano metadane. Schematy metadanych mogą się różnić w przypadku, gdy np. istniejące metadane zostały zaimportowane z innego systemu. Jeśli biblioteka cyfrowa nie zapewnia bezpośredniej obsługi danego schematu metadanych, będzie konieczność zastosowania mapowania. Mapować można za pomocą oprogramowania biblioteki cyfrowej, narzędzi zewnętrznych lub ręcznie.
Jakość obrazu
Jakość obrazów powinna być na tyle dobra, żeby umożliwiała nie tylko przygotowanie wersji do prezentacji w sieci, ale również nadawała się do rozpoznawania OCR i wiernie oddawała cechy oryginalnego obiektu (nadawałaby się do celów długoterminowego przechowywania). Niezależnie od tego czy proces skanowania realizowany będzie w naszej pracowni czy zlecany zewnętrznej firmie należy przeprowadzić dokładną kontrolę jakości.
Uzyskiwanie tekstu cyfrowego
Aby wykorzystać wszystkie zalety dokumentów cyfrowych, obrazy zawierające tekst muszą być publikowane z tekstem w postaci cyfrowej. Jeśli tekst był uzyskiwany automatycznie z użyciem oprogramowania OCR, należy sprawdzić rezultaty rozpoznawania i jeżeli to konieczne wprowadzić niezbędne poprawki.
Tekst cyfrowy
Istnieje kilka ogólnie znanych formatów umożliwiających zapisywanie obrazu wraz z tekstem cyfrowym. Należy się upewnić, że obsługa wybranego formatu jest zapewniana przez oprogramowanie biblioteki cyfrowej oraz zewnętrzne usługi indeksujące np. Google.
Wersja do prezentacji w sieci
Wersje do prezentacji w sieci są umieszczane w bibliotece cyfrowej i prezentowane użytkownikowi. Należy sprawdzić takie parametry pliku jak: jakość obrazu, jego rozdzielczość, rozmiar i format. Parametry te są od siebie wzajemnie zależne i należy sprawdzić, czy żaden z nich nie odbiega od założonej przez nas normy. Odchylenia od normy mogą powodować utrudnienia w dostępie do zasobów.
Jakość wersji do prezentacji w sieci
Obiekty cyfrowe muszą mieć odpowiednią rozdzielczość, umożliwiającą na przykład odczytanie tekstu. Z drugiej strony, rozdzielczość nie może być za wysoka, ponieważ wpłynie to niekorzystnie na wielkość pliku. Wysoki poziom kompresji może z drugiej strony doprowadzić do utraty informacji i zmniejszenia szczegółowość obiektu.
Rozmiar wersji do prezentacji w sieci
Zbyt duży rozmiar pliku może uniemożliwić wyświetlenie lub pobranie pliku przez użytkowników. Oczywiście im wyższy poziom szczegółowości tym lepiej, ale należy pamiętać o zachowaniu równowagi między jakością i rozmiarem pliku.
Format plików wersji do prezentacji w sieci
Oprogramowanie biblioteki cyfrowej musi zapewniać obsługę formatu plików do prezentacji w sieci. Niektórzy użytkownicy mogą mieć problemy z oglądaniem obiektów, jeśli byłaby potrzeba instalowania dodatkowego oprogramowania.
Wersja do prezentacji w sieci - dzielenie na strony, przesyłanie strumieniowe
Niektóre formaty plików umożliwiają wyświetlenie danych przed przesłaniem całości pliku. W przypadku formatów PDF i DjVu można pobrać i wyświetlić tylko wybraną stronę. W przypadku plików dźwiękowych i filmowych można użyć przesyłania strumieniowego. Dla dużych obrazów, takich jak mapy można użyć formatów interaktywnych takich jak Zoomify.
Kopia główna
Kopia główna (egzemplarz wzorcowy, kopia MASTER) jest bardzo istotna w kontekście długoterminowego przechowywania zasobów. Pod żadnym pozorem nie należy usuwać kopii głównej po utworzeniu wersji do prezentacji w sieci.
Oprogramowanie
Udostępnianie zasobów w bibliotece cyfrowej zwykle wymaga odpowiedniego oprogramowania i konta użytkownika. Należy upewnić się, że posiada się prawa wymagane do przeprowadzenia całego procesu publikacji oraz prawa wymagane do udostępnienia zasobu.
Po publikacji
Podgląd
Po opublikowaniu, obiekt powinien być widoczny w bibliotece cyfrowej. Należy sprawdzić, czy jest możliwe wyświetlenie zawartości obiektu na komputerze. Na komputerze w naszej instytucji może być już zainstalowane oprogramowanie potrzebne do wyświetlenia obiektu, dlatego należy jeszcze sprawdzić poprawność wyświetlania obiektu na zwykłym komputerze, umiejscowionym na przykład w bibliotece.
Licencja
Użytkownik musi znać warunki użytkowania obiektu. Informacja na temat licencji musi być jasna i dostarczona razem z obiektem.
Wyszukiwanie lokalne
Należy sprawdzić, czy obiekt może zostać znaleziony na witrynie biblioteki cyfrowej za pomocą wyszukiwania opisu z metadanych. Należy użyć formularzy wyszukiwania prostego i zaawansowanego, na przykład podając tytuł lub nazwisko autora dzieła.
Wyszukiwanie pełnotekstowe
Jeśli obiekt cyfrowy, który został opublikowany zawiera tekst cyfrowy, należy sprawdzić, czy można do niego dotrzeć za pomocą przeszukiwania pełnotekstowego. Wystarczy po prostu skopiować tekst i użyć formularza wyszukiwania. Nie zawsze jest możliwe znalezienie zawartości bezpośrednio po publikacji. Zależy to od oprogramowania biblioteki cyfrowej i uzyskanego rozmiaru pliku.
Wyszukiwarki
Obiekt cyfrowy może być znaleziony przy pomocy wyszukiwarek, jeśli biblioteka cyfrowa jest publicznie dostępna. Nie będzie on widziany bezpośrednio po publikacji. Roboty indeksujące potrzebują trochę czasu na znalezienie i zindeksowanie strony z nowym obiektem.
Agregatory
Agregatory przyczyniają sie do zwiększenia widzialność zasobów w Internecie, a tym samym do wzrostu liczby bezpośrednich użytkowników biblioteki cyfrowej. Należy sprawdzić, czy obiekt jest widoczny w tych serwisach i czy wszystkie dane, np. łącza i metadane są poprawne. Należy pamiętać, że informacja o nowych obiektach nie pojawia się bezpośrednio po publikacji.
Ograniczony dostęp
Jeśli prawa autorskie pozwalają na dostęp do zawartości tylko w obrębie biblioteki, należy upewnić się, że publikacja nie jest ogólnodostępna.