CLEPSYDRA
Data Aggregation and Enrichment Framework
Introduction
Clepsydra is a flexible and scalable system for aggregation, processing and provisioning of data from heterogeneous sources. It was designed and developed to be a basis for services focused on aggregation and enrichment of (meta)data describing on-line collections of cultural heritage digital objects from Polish memory institutions. The first production deployment of this system is the PIONIER Network Digital Libraries Federation.
Below you can find more details on the motivation for the development of the system and very general description of its components. For more information about the system features see below and for its architecture please check the link in the right menu.
Each Clepsydra component which is currently available as an open source has also its own subpage, also available in the menu. These components are independent and we are going to release them one after another, when they will be reaching proper development stage.
Motivation/Features
Functional requirements. While designing and developing the Clepsydra system we wanted to have the possibility to:
-
Store and access large amounts of heterogeneous data records, organized in a way which supports the following:
- data record describes (is representation of) an object - the object can be physical or virtual, it is not important;
- data record has its source - for example it may correspond to a collection, an internet service or an institution;
- object has an identifier which is unique in the scope of particular source of data records;
- data record has its format - for example it may refer to particular binary format (i.e. image/png), a schema of the binary format is XML;
- object can be described (represented by) several data records, but they must have different formats;
- one data record can be derived from another data record through processing, and it is important to have the possibility to follow such relationships.
Users and components of Clepsydra, when accessing the stored data:
- may be interested in various selection criteria based on the above features;
- may want to play active or passive role in the data synchronization process i.e. they will ask on their own for new data records on a regular basis or they will prefer to receive notifications when new/updated records matching specific criteria will be available.
-
Aggregate data records from many different kinds of sources, organized in a way which supports the following:
- data sources may be available through various kinds of protocols;
- data sources may have both passive and active nature i.e. they may accept periodic data synchornisation initiated by external systems or they may want to initiate such acvtivities on their own for example by sending notifications;
- data sources may keep information about all additions/deletions/modifications of data records, but this may not be available or not trustworthy for all data sources;
- data sources may provide data records in various formats and these formats may change/evolve over time;
-
Process data records from one format to another, organized in a way which supports the following:
- processing is composed of relatively small operations which can be joined into more complex streams;
- processing can be dynamically reconfigured and is based on rules describing which processing streams should be applied to which data formats;
- processing is executed automatically, as new data for processing becomes available;
- there should be possibility to store also intermediate results of longer processing streams if needed;
- there should be possibility to significantly increase the available processing capabilities in a dynamic way.
Non-functional requirements. One of the key non-functional aspects of architecture in large production quality systems are the scalability and robustness. Experiences from previously mentioned the Digital Libraries Federation shown us that the most serious scalability issues are related to the increase of the amount of aggregated data or the complexity of data processing workflow. Faults are in majority of cases caused by technical problems or unexpected behavior on the data providers side. Real-life examples can be: hang-outs during data transmission, very long data provider response times or a situation when a data source holding 100 thousand data records, which usually adds or updates up to 300 records daily, suddenly reports that 90% of all objects were updated during single working day. To address this, we designed the aggregation component architecture as a set of independent fault-tolerant agents, and all system components were designed to scale easily. This also included choosing proper underlying technologies like Apache Cassandra.
Another important non-functional requirement is interoperability. As written in the functional requirements section, the designed system should allow to aggregate data from heterogeneous sources, which expresses the need of interoperability in contact with data providers. The interoperability should be also assured on the level of interfaces which will be used by external systems willing to access the aggregated data, offering access in a technology neutral manner. That is why we have decided that all public APIs of Clepsydra should be REST APIs.
The data aggregation, processing and provisioning system should be also ready for several years long operation period possible without major architecture redesigns, therefore maintainability and extensibility, as well as operability, availability and reliability are additional important non-functional requirements which we are trying to address. With the proposed architecture tt should be possible to easily extend the system features in the areas of aggregation, processing and provisioning. The data aggregation and processing components are separated from data provisioning processes, to make possible to access the data even when data aggregation and processing services are not functioning for some reason or are overloaded with unexpected amount of data. On the other hand the increased number of end-users requests should not influence data aggregation operations.
Components Overview
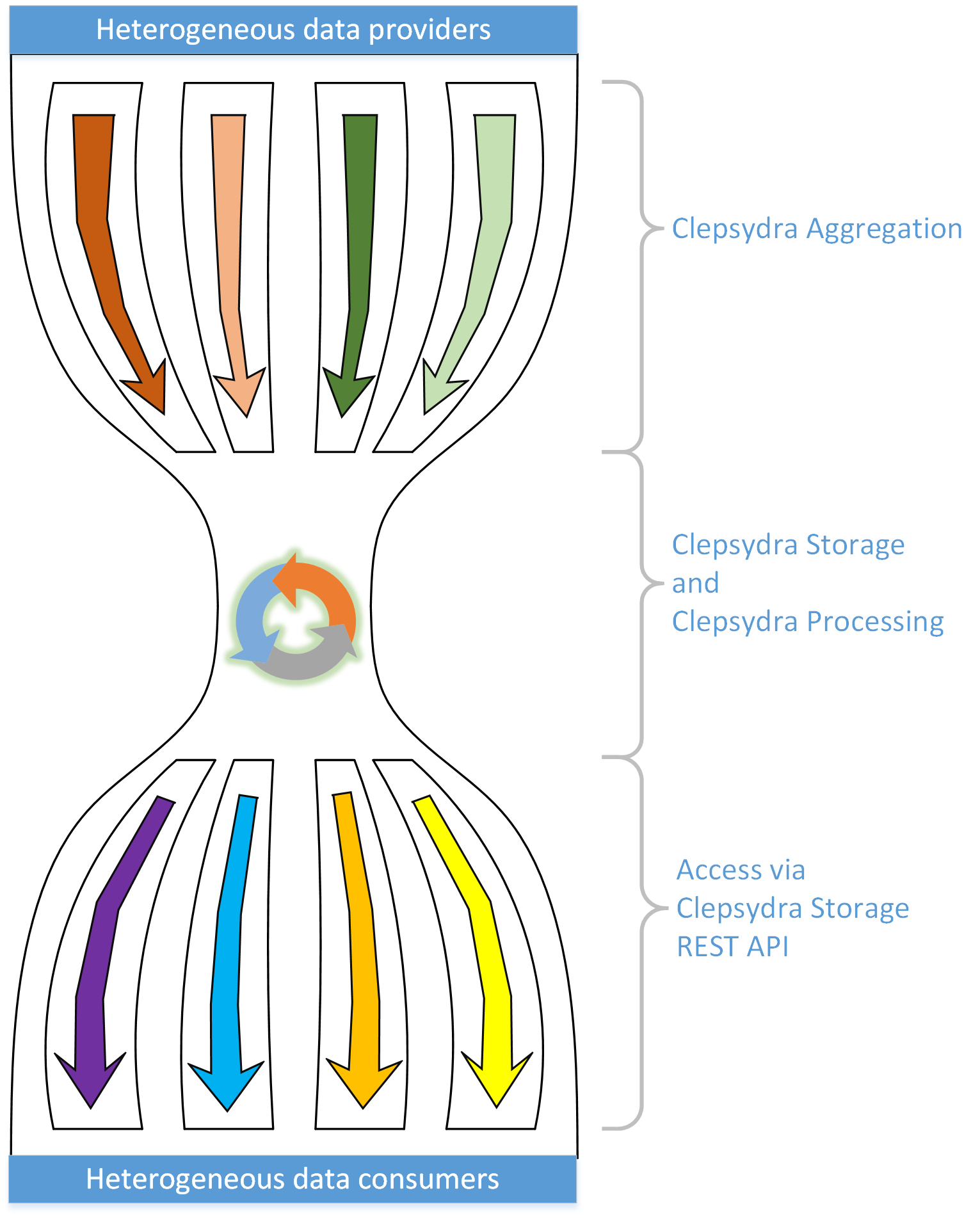
Clepsydra consists of three core components corresponding to the three groups of functional features described above:
- Clepsydra Storage - stores and gives access to data records.
- Clepsydra Aggregation - gets data from various sources to Clepsydra Storage and is responsible for keeping Clepsydra Storage synchronized with the data sources.
- Clepsydra Processing - is responsible for processing data records stored in Clepsydra Storage according to dynamically configured rules. The processed data is stored back to Clepsydra Storage.
The figure below symbolically shows the relation between the three core components of Clepsydra and also explains the name of the project.
Invitation for Cooperation
We are looking forward for any parties intrested in using our product or participating in its development. If you are interested in our project, please feel free to contact us.
About Clepsydra
The project source code is licensed on Apache License, Version 2.0.
Clepsydra Components
- Common
- Storage
More components will be available later on.