CLEPSYDRA
Data Aggregation and Enrichment Framework
Architecture
The overall Clepsydra architecture together with surrounding services (external data providers and data consuming services) is presented in figure below. It consists of five main layers described in the following paragraphs (in bottom-up order). These layers are:
- Source data layer
- Data aggregation and processing layer
- Data storage layer
- Data provisioning layer
- Applications layer
Mapping these layers into Clepsydra components:
- Clepsydra Storage spans from the border between data aggregation and processing layer through the data storage layer up to the data provisioning layer and includes objects database components and message broker components.
- Clepsydra Aggregation and Clepsydra Processing are located in the data aggregation and processing layer.
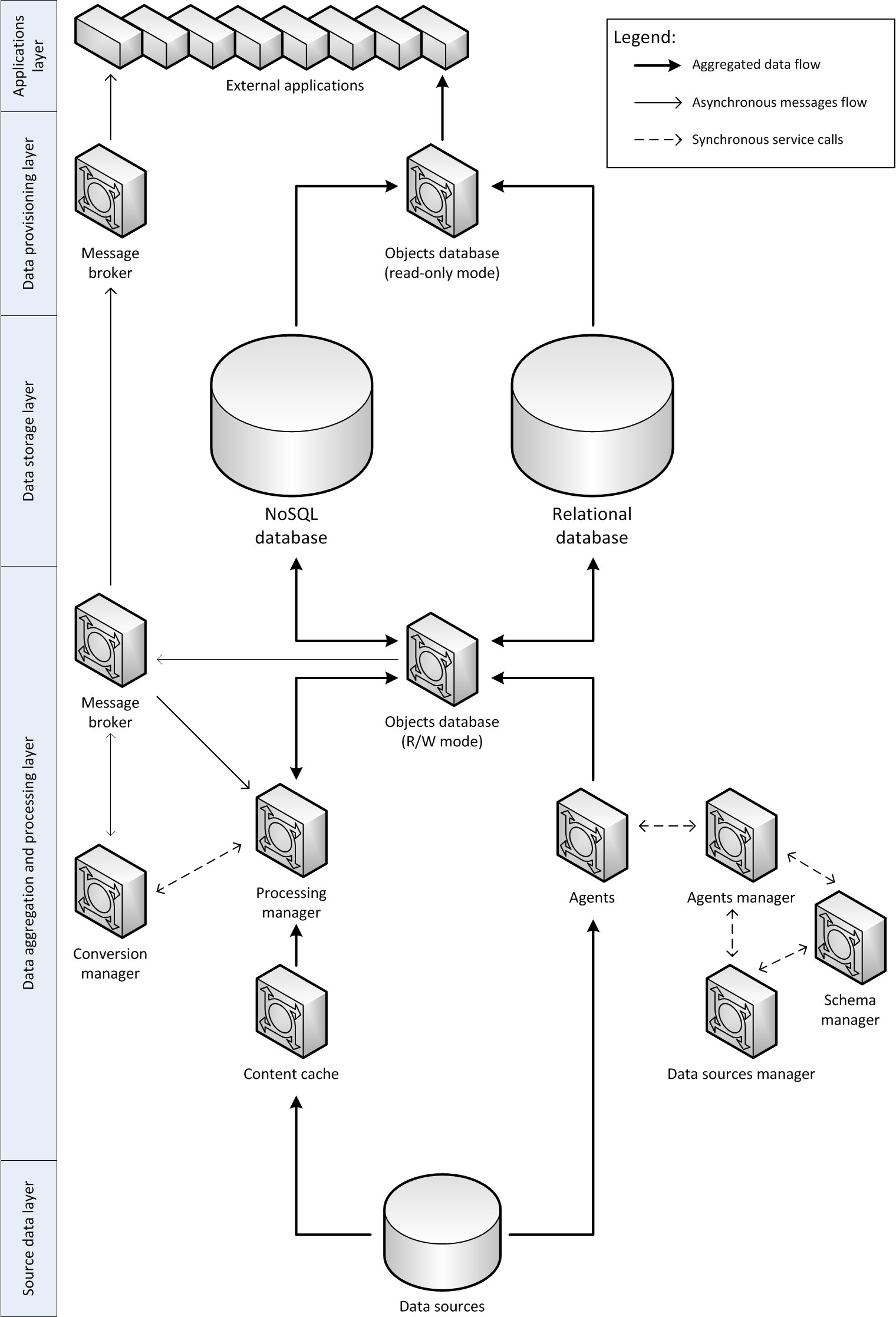
Source data layer. Consists of heterogeneous distributed services giving access to metadata and optionally also to data described by the metadata. Examples of such services are digital libraries (metadata and data) or library catalogues (just metadata, describing physical objects from library collections).
Data aggregation and processing layer. In this layer three groups of components (services) can be distinguished. First group (on the right) is responsible for the aggregation of data. It consists of several agents – services which are able to extract metada-ta from different types of data sources. It was assumed that for each type of data source an agent will be developed capable to communicate with that data source. Of course one type of agent can also be compatible with several types of data sources (for example joint OAI-PMH and OAI-ORE agent). Depending on the needs there can be several instances of agents of the same type deployed, resulting in a cloud of agent services, which are managed by component named agents manager. This component utilizes information from data sources manager and schema man-ager in order to effectively assign agents to data sources. It is also responsible for agents monitoring and collection of statistics from agents. New data source is added by registering it in data sources manager. Schema manager is responsible for infor-mation about data schemas used by particular sources and it enables the automated detection of changes in schema definitions.
Agents store aggregated source data in the component named objects database, which together with message broker forms second group of components in this layer. Objects database is a component responsible for storing data in the data storage layer (described below). It also sends notifications to the message broker about each modification performed on the aggregated data (create/update/delete operations). Other services can subscribe in the broker to receive particular types of notifications.
Such asynchronous notification is the basis for efficient processing of aggregated data, which is done by third group of components in this layer (on the left). Notifications about new or updated data is received by conversion manager, which allows to define processing paths. If the notification is related to creation or update of a metadata record which type is in the beginning of one of de-fined processing paths, such path is applied to this record. In order to do so, the con-version manager sends proper processing order message to the message broker. Such messages are received by one of the processing managers (there can be many in-stances of processing managers) which are responsible for getting the metadata rec-ord from objects database, processing it according to chosen path and storing the outcome back to the objects database. If in some cases the processing requires down-load of additional digital content from the data source (e.g. in case of thumbnail generation), then optional content cache component may be used.
Data storage layer. The objects database in the previously described layer stores data in the data storage layer. This layer consists of two types of databases: NoSQL database and relational database. The relational database is designed to store only basic information about each aggregated metadata record or other kind of object’s representation. This information includes:
- the id of object which is connected with the representation (provided by data source),
- the unique ID of the representation in the data storage layer,
- date of its first appearance in the storage layer,
- date of last modification of the representation,
- date of deletion (if the object was deleted and is no longer available),
- current checksum,
- data source,
- data schema,
- information if the particular representation is in its source form, or if it is an out-come of one of defined processing paths.
The NoSQL database should be used to store the representations of objects. Such mixed approach was chosen to allow easy selective queries on the aggregated data without the need of duplication of the data in the NoSQL database for the purpose of every possible selection criteria.
In the basic variant instead of NoSQL database, a distributed file system could be used, but the database gives significantly better possibilities for extension of the data model in the future (for example when authorization will be required on the single object’s representation level).
Data provisioning layer. Access to aggregated and processed data is offered via the data provisioning layer. This layer contains duplicated instances of two components from the data aggregation and processing layer: objects database and message bro-ker. Objects database uses data storage layer to give access to the data (in read-only mode). The second message broker copies from the first one messages about new, updated or deleted entries in the objects database and exposes them for interested external applications. Notifications generated by the conversion manager (and po-tentially other internal system notifications) are ignored by the data provisioning message broker.
Applications layer. Applications layer is a place for external services which want to access resources aggregated and processed by the described system. Such applica-tions can use services from the data provisioning layer. Examples of such applica-tions are described in section 5 of this paper.
Selected non-functional aspects.
In order to assure interoperability it was decided that REST protocols will be used to expose functionality provided by all system components, especially the objects database API. The multi-tiered architecture is constructed in a way which allows data provisioning layer and data aggregation and processing layer to work independently. For both these layers the data storage layer is necessary, but modern relational and NoSQL database system can be configured and deployed in a way which ensures very high availability (including database clusters with data synchronization between nodes).
Introduction of several parallel processing managers and data aggregation agents makes the system more immune to unexpected behavior of data sources, or data anomalies in the aggregated data. Beside it allows to achieve better scalability of the system, also because the workload distribution related to data processing is handled by the asynchronous messaging system, in which a single queue of messages (repre-senting data processing tasks) can be serviced by a group of processing managers. The size of such group can be easily scaled up or down as needed without system reconfiguration – it is just a matter of subscription of particular processing manager in the message broker.
Additional instances of message broker and objects database make the security aspects easier to achieve, as the instances located in the data provisioning layer work in the read-only mode. Because of the use of REST protocols, such read-only mode can be achieved as easily as by proper firewall configuration (e.g. by not allowing HTTP requests using other methods than GET). The use of NoSQL database gives the possibility to introduce more complex authorization information in the future, but of course in such case adaptation of the objects database will be also needed.
Agents manager and conversion manager services makes the entire services infra-structure more maintainable and operable, as they were designed to monitor the data aggregation and processing components, provide overview of the current system state and alert administrators when needed.
About Clepsydra
The project source code is licensed on Apache License, Version 2.0.
Clepsydra Components
- Common
- Storage
More components will be available later on.