

jMet2Ont is a mapping tool that transforms XML-based metadata to ontology-based formats. The source metadata format may be flat (e.g. Dublin Core) or hierarchical (e.g. MARC/XML).
The mapping rules are described in an XML file. To use the mapper you do not need any programming knowledge. You can find full specification of the XML rule syntax in the Documentation section.
The tool is available for free and on an open source license.
If you need a feature that the mapper does not offer yet, you can do one of two things: request a feature (see the Contact section), or Download and extend the sources.
jMet2Ont has been created at Poznan Supercomputing and Networking Center, in the course of the SYNAT project, after analysis of existing mapping tools.
SYNAT is a Polish national research project aimed at the creation of universal open repository platform for hosting and communication of networked resources of knowledge for science, education, and open society of knowledge. It is funded by the National Centre for Research and Development (grant no SP/I/1/77065/10).
Internally, jMet2Ont uses Sesame.
The mapper transforms (meta)data in XML-based schemas:

using mapping rules defined in an XML file:

to RDF triples in any of the popular formats (BINARY, N3, NTRIPLES, RDFXML, TRIG, TRIX, TURTLE), building knowledge bases:
jMet2Ont has been created as an answer to a real demand in the SYNAT project. We specified a set of requirements for an XML to ontology RDF -mapper, and found that no mappers satisfy all of them. You can see the requirements reflected in different sections of the User Documentation page.
XSLT is a Turing-complete declarative language, which means that at least theoretically it is able to perform any calculation that can be performed by a modern computer program. However, expressing advanced mapping rules in this language requires vast programming knowledge and leads to extremely complex expressions, as XSLT is a general XML-to-XML transformation tool and not a Semantic-Web-oriented one. The resulting files (even though we have not seen an XSLT transformation satisfying all of our requirements) are too complex for digital humanities experts to read.
The most important feature that we found was missing in most tools is the possibility to treat certain pieces of information distributed over a metadata record as describing one knowledge base object (i.e. the same instance of an OWL class).
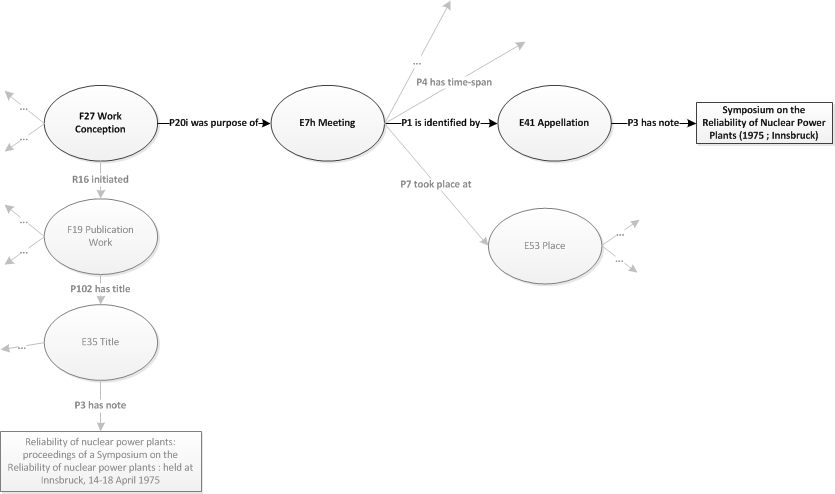
This is the reason why three types of identifiers were created:
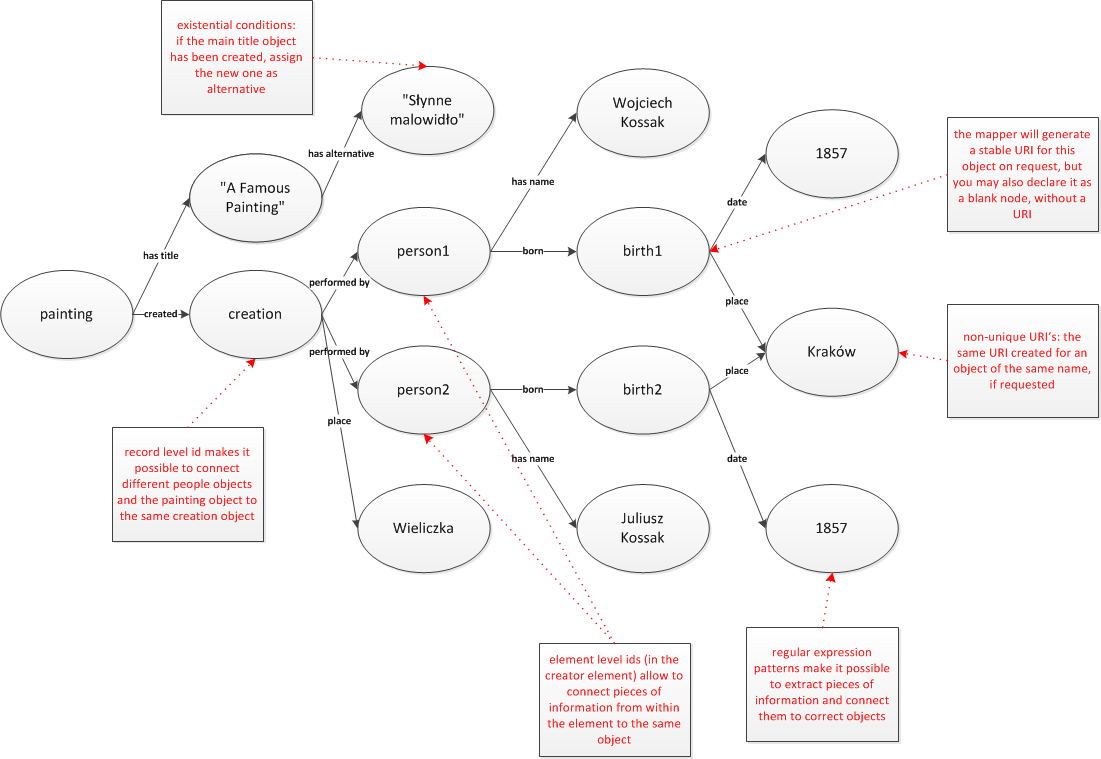
The jMet2Ont mapper is based on the notion of ontology paths (see jMet2Ont Input and Output). Different parts (based on a regular expression) of the element contents are mapped to different paths. You can assign identifiers to different elements on the path, saying, for instance, that the "place" object created as a result of parsing the contents of one element is the same "place" object that appears somewhere else in the record (record level id). You can say that all information from one occurrence of an element and its subelements describe one person, but another occurrence is about someone else (element level identifier). In some metadata schemas it happens that the first occurrence of element A corresponds to the first occurrence of element B, and their second occurrences also are connected. This is what iterable identifiers are for.
For example, based on the following XML record:
<record> <title>A Famous Painting<title> <title>Słynne malowidło</title> <placeOfCreation>Wieliczka</placeOfCreation> <creator>Wojciech Kossak (1875, Kraków)</creator> <creator>Juliusz Kossak (1875, Kraków)</creator> </record>
You can create the following knowledge base fragment:
The User Documentation page lists all current features of the mapper.