

The tool is provided as an executable jar.
To perform the mapping, you have to run the Windows console (type CMD in the Start menu Search box). In the console, you run the mapper by giving the following command:
java -jar jMet2Ont-X.X-executableJar.jar properties-file source-file target-file
where:
A more user-friendly release with a graphical interface is expected in the future.
jMet2Ont uses UTF-8 encoding.
The best example of how to run the jMet2Ont mapper can be found in the pl.psnc.synat.mapper.main.Runner class which is the command-line runner.
You have to make the following sequence of calls:
If you wish to modify the mapper behavior, see the Programmatic Extensions section.
The DTD (Document Type Definition) describes the correct structure of a valid XML document. This section provides the DTD's for all mapping rule files (main mapping rules file, external reusable sub-paths file, external value map file). In many cases you will only need to define the main mapping rules file.
The mapping rules syntax is described and explained in detail in the remaning part of this document.
The DTD's are here to make it easier for you to check the validity of your mapping files. When your file is ready, you can validate it against a DTD using one of the available tools, such as Validome.
However, a validated file may still contain some logical errors that only the mapper will be able to detect.
Available here: ./mapping.dtd
Available here: ./reUsableSubPaths.dtd
Available here: ./valueMap.dtd
<!ELEMENT Map (map)> <!ELEMENT map (entry*)> <!ELEMENT entry (key?,value?)> <!ELEMENT key (#PCDATA)> <!ELEMENT value (#PCDATA)>
The mapping rules are based on the concept of a mapping path. Below is a very simple example, consisting of a record mapping description, a sample record, and the result in both RDF and visual format.
You can make the rule files more readable using XML Entities.
This is a sample mapping rule for a record containing only the title element:
<recordMapping recordTag="record">
<namespaces>
<namespace prefix="frbroo" ns="http://erlangen-crm.org/efrbroo/120131/" />
<namespace prefix="cidoc" ns="http://erlangen-crm.org/current/" />
<namespace prefix="dc" ns="http://purl.org/dc/elements/1.1/" />
</namespaces>
<elementMapping elementName="dc:title">
<patternToPaths>
<pattern prior="1">(?s)(.*)</pattern>
<path no="1" type="literal">
<pathElement>frbroo:F19_Publication_Work</pathElement>
<pathElement>frbroo:R3_is_realised_in</pathElement>
<pathElement recordLevelId = "infObj">frbroo:F24_Publication_Expression</pathElement>
<pathElement>cidoc:P102_has_title</pathElement>
<pathElement blank="true">cidoc:E35_Title</pathElement>
<pathElement>cidoc:P3_has_note</pathElement>
</path>
</patternToPaths>
</elementMapping>
</recordMapping>
The contents of the record are matched against a regular expression pattern. In this case, it is the (?s)(.*) pattern matching all elements contents, even if there are line breaks.
The pattern contains so-called capturing groups (in parentheses). Each group corresponds to one mapping path. In this case there is only one group, and hence only one mapping path.
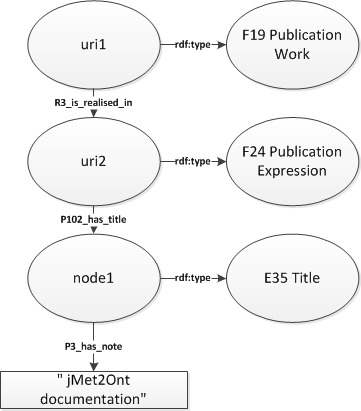
The path describes the ontology-described knowledge base objects to which the piece of information from the source metadata record applies. There is a Publication Work object (in the FRBR sense; it is an abstract work created by an author). The object participates in the R3_is_realised_in relation with another object, of type Publication Expression (in FRBR this is an edition of the work, still at the abstract level). The Publication Expression object has a title. The example is based on the CIDOC CRM ontology, in which a title is an object itself. Finally, the contents of the captured group are connected to the title object with the P3_has_note relation.
There are some attributes associated with some of the path elements. blank means that the element will not have its own URI: it is going to be a blank node in the ontology. recordLevelId is an identifier assignment. If this identifier appears anywhere else in the mapping rules file, the same object will be used. Note that blank nodes may also have this kind of identifiers.
This is a sample record, containing only the title element:
<record>
<title>
jMet2Ont documentation
<title>
</record>
This is the resulting RDF in TriX format:
<?xml version='1.0'?>
<TriX xmlns='http://www.w3.org/2004/03/trix/trix-1/'>
<graph>
<triple>
<uri>http://sample-namespace/F19_Publication_Works/uri1</uri>
<uri>http://www.w3.org/1999/02/22-rdf-syntax-ns#type</uri>
<uri>http://erlangen-crm.org/efrbroo/F19_Publication_Work</uri>
</triple>
<triple>
<uri>http://sample-namespace/F19_Publication_Works/uri1</uri>
<uri>http://erlangen-crm.org/efrbroo/120131/R3_is_realised_in</uri>
<uri>http://sample-namespace/F24_Publication_Expressions/uri2</uri>
</triple>
<triple>
<uri>http://sample-namespace/F24_Publication_Expressions/uri2</uri>
<uri>http://www.w3.org/1999/02/22-rdf-syntax-ns#type</uri>
<uri>http://erlangen-crm.org/efrbroo/120131/F24_Publication_Expression</uri>
</triple>
<triple>
<uri>http://sample-namespace/F24_Publication_Expressions/uri2</uri>
<uri>http://erlangen-crm.org/current/P102_has_title</uri>
<id>node1</id>
</triple>
<triple>
<id>node1</id>
<uri>http://www.w3.org/1999/02/22-rdf-syntax-ns#type</uri>
<uri>http://erlangen-crm.org/current/E35_Title</uri>
</triple>
<triple>
<id>node1</id>
<uri>http://erlangen-crm.org/current/P3_has_note</uri>
<plainLiteral>jMet2Ont documentation</plainLiteral>
</triple>
</graph>
</TriX>
This is a visualisation of the resulting mapping path:
A record mapping is a set of elements mappings. A record mapping, one per file, is represented by a pair of recordMapping tags.
The recordMapping tag has one required tag: recordTag. This tag defines the name of the tag in the source metadata format that encloses one record data. The record tag name may be overriden in the Configuration File.
The recordMapping may enclose four other tags:
The mapping of a single element is described using the elementMapping tag. It has one required attribute: elementName. It is the fully qualified name of the XML element in the source metadata format.
An element mapping has to contain at least one occurrence of one of the following two elements: * one or more patternToPaths tags, describing the path(s) to which the contents of the elements should be mappped (see The Pattern, The Path, and Conditions) . * one or more nested element mappings, enclosed with the same elementMapping tag.
This section contains an example of an element mapping with a nested element mapping. Note that the element contains both text content and a nested element. The mapping rule handles both those items.
An element with both text content and a nested element:
<withNestedWithContent>
mob
<nested>
kidnapping
</nested>
<nested>
blackmail
</nested>
</withNestedWithContent>
An example of a mapping for the above schema:
<elementMapping elementName="withNestedWithContent">
<patternToPaths>
<pattern prior="1">(.*)</pattern>
<path no="1" type="literal">
<pathElement elementLevelId="group" elementName="withNestedWithContent">cidoc:E74_Group</pathElement>
<pathElement>cidoc:P3_has_note</pathElement>
</path>
</patternToPaths>
<elementMapping elementName="nested">
<patternToPaths>
<pattern prior="1">(.*)</pattern>
<path no="1" type="literal">
<pathElement elementLevelId="group" elementName="withNestedWithContent">cidoc:E74_Group</pathElement>
<pathElement>cidoc:P144i_gained_member_by</pathElement>
<pathElement>cidoc:E5_Event</pathElement>
<pathElement>cidoc:P3_has_note</pathElement>
</path>
</patternToPaths>
</elementMapping>
</elementMapping>
In some schemas, like MARC/XML, the element name is not enough to apply mapping semantics. Sometimes the meaning of an element is based on the element name but also the tag values. In a situation like this, you can provide the tag values required for the specified mapping paths to apply. The attribute values are provided within the attrValues tag, like in the following example:
<elementMapping elementName="datafield">
<attrValues>
<attrValue attr="tag" value="041" />
</attrValues>
<patternToPaths>
...
</patternToPaths>
</elementMapping>
Note that the attribute value is a regular expression, so you can provide a pattern of values (e.g. [a-c|e], meaning a,b,c, or e).
Caution: empty attribute contents and lack of the attribute are considered the same situation.
It also is possible to map attribute contents the same way element contents are mapped. The mapping paths look the same and use regular expression groups in the same way. The attr attribute of the path element connects the path to an attribute.
Example:
<elementMapping elementName="ns1:vitalDatesCreator">
<attrValues>
<attrValue attr="birthdate" value="(.*)" />
...
</attrValues>
<patternToPaths>
<pattern prior="1">.*</pattern><!--empty element! only attributes matter!-->
<path attr="birthdate" no="1" type="literal">
<pathElement elementLevelId="creator" elementName="ns1:indexingCreatorSet">cidoc:E21_Person</pathElement>
<pathElement>cidoc:P98i_was_born</pathElement>
<pathElement>cidoc:E67_Birth</pathElement>
<reUsableSubPath name="hasTimeSpan" />
</path>
...
</patternToPaths>
</elementMapping>
As you have seen above, the required attributes are defined using regular expressions. This is not the case with element names, but there is one trick you can do. If a number of elements are mapped exactly the same way, you can define one mapping for all of them, using the | syntax:
<elementMapping elementName="same1|same2">
<patternToPaths>
<pattern prior="1">(.*)</pattern>
<path no="1" type="literal">
...
</path>
</patternToPaths>
</elementMapping>
Advanced: the element mapping rule defined for an element with a set of attributes is stored as one instance for all attributes matching the regular expression. This means that if the rule contains a singleton path, the contents will be concatenated even if the attributes were not equal. In case of of identical mappings for different elements, the rules are duplicated and stored separately, which means that any singleton path will only concatenate the contents from one of the elements.
If you want to ignore the contents of an element and all its children without getting warnings about the lack of mapping for it, use the ignored attribute like this:
<elementMapping elementName="irrelevantContents" ignored="true" />
Another way of marking an element as ignored is to define a pattern with no groups. The difference is that then the mapper will try too look for mappings for the element's children.
The pattern is a regular expression with groups. Each groups must have a corresponding mappint path. The pattern tag has one required attribute: prior. If there is more than one pattern (and thus more than one patternToPaths tag), the evaluation order is based on the prioritites. The first matching pattern is used, so remember to always give the highest priority (lowest number) to the least general pattern.
Here are some regular expression patterh examples:
Try to use non-greedy quantifiers (*? instead of *) in the regular expressions where possible. If the last example in the above section used a greedy quantifier, the contents the element would all match the first group, and the other groups would be empty.
If you need to use a group in the regular expression, but you do not want to map it to any paths, you can use a non-capturing group, marking it with (?:) instead of ().
An example:
(a(?:b*))+(c*)
For the abbabc string, the captured groups are:
If the matched group is empty or contains only white characters, the corresponding path will be ignored.
If you want to ignore the contents of an element without any warnings from the mapper, define a pattern to paths pair in which there are no capturing groups in the pattern and there are not paths.
The path tag has to required attributes:
There can be more than one path with she same value of the no attribute: the corresponding captured group will then be reused.
There are five types of paths:
This path consists of a sequence of pathElement tags. Based on those elements the mapper builds and related knowledge base objects. The following statements must be true for any given literal path:
It is a literal path that is created only once. It the patternToPaths mapping rule is applied more than once, new occurrences will not lead to a creation of new objects. Instead, the value of the element will be added at the end of the literal resulting from the previous mapping. You can define a joiner for a singleton path: be default the values are concatenated with an empty string.
If the singleton paths contains Identifiers, concatenation will only happen when the current id values are the same.
A URI path is very similar to a Literal Path. The differences are as follows:
A path which ignores the contents of the captured group. It starts and ends with a class (or instance) element.
A case path does not introduce the value from the captured group to the knowledge base. Instead, depending on the value, it introduces relations between existing objects, bery much like the Static Path. You can mark one of the case options as default.
You can define empty case paths.
Example:
<pattern prior="1">(?s)^.{6}([aefk])(.).+</pattern>
<path no="1" type="case">
<case>
<caseValue>a</caseValue>
<casePath>
<pathElement recordLevelId = "mainDescribedObject">cidoc:E89_Propositional_Object</pathElement>
<pathElement>cidoc:P2_has_type</pathElement>
<pathElement instance="true">http://purl.org/dc/dcmitype/Text</pathElement>
</casePath>
</case>
<case>
<caseValue>e</caseValue>
<casePath>
<pathElement recordLevelId = "mainDescribedObject">cidoc:E89_Propositional_Object</pathElement>
<pathElement>cidoc:P2_has_type</pathElement>
<pathElement instance="true">http://dl.psnc.pl/schemas/namedIndividuals/dcmitype_extended#Map</pathElement>
</casePath>
</case>
<case>
<caseValue default="true" />
<casePath />
</case>
</path>
Path elements are further defined with a set of mostly non-required attributes. The semantics of those attributes are described in this section.
If the blank attribute of a pathElement is set to true, the corresponding knowledge base object will not have its own URI. Instead, it will be a blank node.
Default value is false.
If the unique attribute of a pathElement is set to true, the mapper will ensure that its URI does not repeat in the knowledge base.
The URI's are based on the class of the element and the contents of the corresponding captured group, so if the attribute is set to false, the URI's of very similar elements may be repeated.
Default value is true.
If the instance attribute of a pathElement is set to true, the provided URI will not be treated as a class name, but as an instance (e.g. from a vocabulary loaded into the knowledge base).
Default value is false.
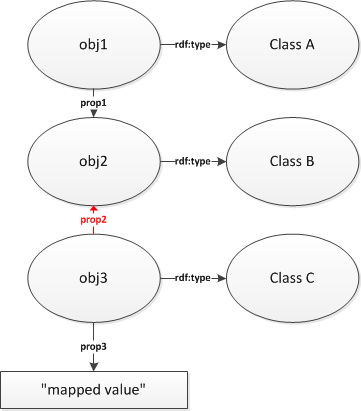
This is the only one mapping path element attribute that applies to property name elements.
When declaring a mapping path for an ontology in which not every property has an inverse, you may find yourself in the situation when the property works the other way round. If the property should connect the second element with the first one, set the reverse attribute to true.
Default value is false.
Example:
<pathElement>class A</pathElement> <pathElement>prop 1</pathElement> <pathElement>class B</pathElement> <pathElement reverse="true">prop 2</pathElement> <pathElement>class C</pathElement> <pathElement>prop 3</pathElement>
Often mapping paths are repeated throughout the mapping rules document. It is possible to extract such paths to an external file. The DTD of such file is given in the External Reusable Sub-Paths DTD section. The external sub-paths file location can be an absolute path or a path relative to the main mapping rules file.
This section given a simple example of an external mapping sub-path to which you can refer by its name.
Sample contents of an external sub-paths file:
<reUsableSubPaths>
<reUsableSubPath name="hasTimeSpan">
<pathElement>cidoc:P4_has_time-span</pathElement>
<pathElement>cidoc:E52_Time-Span</pathElement>
<pathElement>cidoc:P78_is_identified_by</pathElement>
<pathElement blank="true">cidoc:E49_Time_Appellation</pathElement>
<pathElement>ext:P3h_has_note</pathElement>
</reUsableSubPath>
</reUsableSubPaths>
Call to an external sub-path:
<recordMapping reUsablePathsFile="./reUsableSubPaths.xml" recordTag="..."> ... <pathElement recordLevelId = "infObj">frbroo:F24_Publication_Expression</pathElement> <pathElement>cidoc:P16i_was_used_for</pathElement> <pathElement>ext:E7a_Becoming_Available </pathElement> <reUsableSubPath name="hasTimeSpan"/> ...
It is possible to add a string at the beginning or at the end of the mapped value using the startWith and endWith path attributes.
Class name path elements may be assigned identifiers. If the same identifier is repeated in different places of the mapping rules file, the mapper, after encountering the id for the second time, will not create a new object, but reuse the existing one. This is one of the most crucial requirements while mapping to an ontology-based formats. Using identifiers, it is easy to model a resource's participation in different relations.
Sometimes the contents of an element are separated into may groups, containing different kinds of information about an object. For instance, the creator element may contains the name of a person and the person's birth date. We want to create two separate paths, assigning data to the same object.
To introduce an element-level id you have to use the elementLevelId tag, providing the id.
Additionally, you can add the elementName tag. It defaults to the current element. This tag defines the scope of the identifier: in hierarchical schemas the same element-level id may be valid in many sub-elements.
Example:
<pathElement elementLevelId="creator" elementName="dc:creator"> cidoc:E21_Person </pathElement>
Note that two occurrences of the same ID may belong to path elements with different class names. It is the user's responsibility to make sure that those classes are consistent.
A record-level identifier is very similar to an Element-Level Id, but it is valid throughout the whole record. You declare it using the recordLevelId attribute.
In some rare cases you may want to define two record-level ids for the same element - they should be separated with a semicolon (recordLevelId="id1;id2"). If the URI's for both id1 and id2 have already been created, they will be merged when such a path element is obtained, and they will be replaced in the statements already generated for this record.
This is an advanced type of identifier that you probably will not need very often.
There are cases in which two separate elements that share no common parent other than the document root are related to each other in such a way that the first occurrence of element 1 corresponds to the first occurrence of element 2, the same hold for second occurrences and so on. This relation may hold e.g. between MARC 21 datafield 300 (physical description), subfield e (accompanying material) and contents of datafield 538 (system details note).
In such cases you can use a record-level id with iterable attribute set to true.
It is advised to also define the elementName for this identifier: the id will be iterated each time the mapper leaves the attribute, and the iteration is set to 1 at the first occurrence of the element. The default element name is the current one.
Consider the following XML file:
... <elem1> <subel>Name and surname 1</subel> <subel>Name and surname 2</subel> <subel>Name and surname 3</subel> </elem1> ... <elem2> <subel2>date of birth 1</subel2> <subel2>date of birth 2</subel2> <subel2>date of birth 3</subel2> </elem2> ...
You can connect the names to birth dates using iterable record-level ids:
... <!--subel mapping in elem1--> <pathElement recordLevelId = "person" iterable="true"> cidoc:E21_Person </pathElement> ... <!--subel2 mapping in elem2--> <pathElement recordLevelId = "person" iterable="true"> cidoc:E21_Person </pathElement> ...
You can further restrict the iteration giving attributes together with elementName, like this:
<pathElement iterable="true" recordLevelId="addContent"
elementName="http://www.loc.gov/MARC21/slim/subfield(code=e;ind=1)">
frbroo:F23_Expression_Fragment
</pathElement>
And/or force iteration reset with the resetOn attribute. Then the next occurence of the identifier within the same element will be treated as the first one. It is useful for instance in MARC/XML records where are elements have the same name (subfield). You can reset the iteration after encountering the datafield parent tag.
<pathElement iterable="true" recordLevelId="addContent" resetOn="http://www.loc.gov/MARC21/slim/datafield"
elementName="http://www.loc.gov/MARC21/slim/subfield(code=e;ind=1)">
frbroo:F23_Expression_Fragment
</pathElement>
If you want the identifier to be iterated at each occurence within a scope (especially one element scope), you can pass "*" as the element name. Remember to set the resetOn property then - otherwise the identifier will never be reset (each iterated id will be used only once, rendering its existence useless).
The object's URI is generated when the identifier is first encountered. Sometimes another occurrence contains data that would allow for a more representative URI (remember, the captured group value is used to generate the URI). If you want the id to be regenerated in a more representative location, mark the location with the idDataSrc attribute set to true.
The condition tag may appear within a patternToPaths element.
There are three types of conditions, corresponding to three types of identifier:
If the patternToPaths element contains a declarations like this:
<condition type="recordLevelId">issnMain</condition>
it means that the pattern will only be evaluated if an object with the given id has already been created. If not, the next pattern will be checked.
Such existential conditions have been introduced for situations in which the first occurence of an element is treated differently, e.g. for titles and alternative titles.
Resetting ids is necessary only in very specific scenarios.
You can use the resetIds attribute of a pathElement to reset the saved record level id or element level id. The URI of the element that has the attribute will be the new ID value.
Caution! This functionality has been designed to help deal with recursive elements. This does not change the URI's of the resources that have already been assigned that id (to do that, use idDataSrc). Instead, it causes all references to this id from now on to correspond to the new URI.
If you use it with an iterable id, the id will be iterated.
If two elements have the same mapping, there are two things you can do:
<elementMapping elementName="dc:title|dc:alternative">
To define a reusable mapping, you assign an identifier to an element mapping (mapingId attribute), and later refer to it from the element that wants to reuse the mapping (reuseMapping attribute).
Such references are evaluated lazily, which means that they can be used to describe mappings of recursive elements.
Example:
<elementMapping elementName="mappingWithId" mappingId="id1">
<patternToPaths>
<pattern prior="1">(.*)</pattern>
<path no="1" type="literal">
<pathElement>cidoc:E5_Event</pathElement>
<pathElement>cidoc:P3_has_note</pathElement>
</path>
</patternToPaths>
</elementMapping>
...
<elementMapping elementName="reusingWithIdNested" reuseMapping="id1" />
The mapper is namespace-aware, so you can use XMLNS namespaces in the source XML data file.
If you do not want to repeat the namespaces in the mapping rules file, you have to define the prefixes using the namespaces nad namespace tags:
<namespaces> <namespace prefix="frbroo" ns="http://erlangen-crm.org/efrbroo/"/> <namespace prefix="marc" ns="http://www.loc.gov/MARC21/slim/"/> </namespaces>
You can use the defined prefixes in the elementName attribute and on mapping paths, for instance:
<pathElement iterable="true" recordLevelId="addContent"
elementName="marc:subfield(code=e;ind=1)">
frbroo:F23_Expression_Fragment
</pathElement>
You can use those prefixes in external sub-paths file, but they have to be defined in the main mapping rules file.
It is possible to create maps that change values into other values; or literal values into URI's.
In the mapping rules file you have to declare the map using the externalMap tag:
<recordMapping recordTag="record">
<externalMaps>
<externalMap name="countryCodes" file="maps/countryCodesMap.xml" />
</externalMaps>
<elementMapping elementName="datafield">
...
The map file location can be an absolute path or a path relative to the main mapping rules file.
The DTD for the map file is given in the External Value Map DTD section.
An external map may look like this:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Map>
<map>
<entry>
<key>key1</key>
<value>value1</value>
</entry>
<entry>
<key>klucz2</key>
<value></value> <!--ignored-->
</entry>
<entry>
<value>default</value>
</entry>
</map>
</Map>
To refer to the map on a path:
...
<patternToPaths>
<pattern prior="1">(.*)</pattern>
<path no="1" type="literal" mapName="countryCodes">
<pathElement...
...
As seen in the example above, it is possible to define a default value, skipping the key.
If a default value is not defined, the mapper will leave the original value. This may lead to a mapper error if the map changes literal values into URI's, and the mapper expects a URI value.
As seen in the example above, it is possible to ignore some values, skipping the value declaration for a given key.
If you want to ignore all unknown keys, add the following snippet to your map:
<entry> </entry>
Instead of maps, one may use calculations, for instance to change Degress/Minutes/Seconds geographical coordinates to their decimal representation.
A calculations is defined as follows:
<calculations>
<calculation name="dms2DecimalDegreesNE" par1="degrees" par2="minutes" par3="seconds" decimalPlaces="4">
<result>degrees + minutes / 60 + seconds / 3600</result>
<calcPattern>(...)(..)(..)</pattern>
</calculation>
...
</calculations>
Where:
To perform a calculation, you have to refer to it from a mapping path:
<pattern prior="1">(?s)E(\d+)</pattern>
<path no="1" type="literal" calculation="dms2DecimalDegreesNE">
...
The calculation defined above will convert the E0141000 value to 14.1694.
Note that the path will pass the value of ONE group - division of this group among patameters is defined within the calculation.
If a calculation was combined with a value map, the value map transformation would be performed earlier, and the calculation would be performed on the result.
To run the mapper as a command line tool you need to prepare a configuration file providing basic information for the mapper. This section described the properties defined in the configuration file.
The file has the Java properties file syntax. A simple example:
rulesFile=C:/mapper2/plmetEse2Cidoc.xml kbNameSpace=http://dl.psnc.pl/kb/ kbContext=http://dl.psnc.pl/mapper/ recordTag=http://dl.psnc.pl/schemas/plmet/joinedMetadata
| Property Name | Meaning |
|---|---|
| rulesFile | location of the rules file on disk |
| Property Name | Meaning | Default Value |
|---|---|---|
| recordTag | the name of the tag that wraps one record data | read from the rules file |
| rdfFormat | triples file format (RDF/XML, N-Triples, Turtle, N3, TriX, TriG) | TRIX |
| kbNameSpace | the namespace for new objects | http://www.example.com/ - you do not want this |
| ontologyFiles | semicolon-separeted names of files defining your ontology : if you provide them, the mapper will perform some validation of the mapping rules | null |
| inverseProcessing | see Inverse Processing | false |
| managerClass | see Programmatic Extensions | pl.psnc.synat.mapper.core.NameSpaceInMemoryManager |
| kbContext | context the triples will be put ine | null |
If you plan to use the mapper as a ready, command line tool, you can skip this section. It is dedicated to programmers who wish to extend the possibilities of the mapper.
The mapper creates URI's for new object based on the provided main knowledge base namespace, the class the object belongs to, and the textual contents of the element that leads to the object creation. The URI's are stable, i.e. they will be the same after each run of the mapper, provided the metadata record does not change.
If you do not like the URI's generated by the mapper, or you have strict rules of URI creation for your data, you can do it easily by extending the pl.psnc.synat.mapper.core.NameSpaceManager abstract class or the pl.psnc.synat.mapper.core.NameSpaceInMemoryManager concrete class and setting your class as the managerClass for the mapper.
You should implement or override the createURI methods.
Originally the mapper has been used to create a knowledge base described with the CIDOC CRM ontology. In this ontology, most properties have their inverses. A property name always starts with PX_, where X is a number. Inverse properties start with PXi_. In our use case it was important that the mapper only produces the basic property triples (without 'i'), mostly because we did not want to turn reasoning on at too early a stage, but wanted to be able to query the repository efficiently.
If you have a similar use case, and want the mapper to always use the original property (reversing the triple, of course), here is what you have to do:
The mapper puts all triples in a context (named graph). You define the context in the properties file (or mapper constructor), be default it is null.
If you wish to apply a more advanced context logic and base the context on the contents of the metadata record, the Simple way that you can do it is by overriding the setMapperContext(String fullElementName, String elementContents) in pl.psnc.synat.mapper.core.XmlToOntMapper. The method has en empty body in the mapper.